
Wrapper methods evaluate all possible combinations of features against an evaluation criterion (such as accuracy, precision, or R-squared). They iteratively add or remove features to gauge their utility based on the model’s performance. Because they consider the interaction between features, wrapper methods often result in better performance. But are computationally more expensive than filter methods.
Let us use houseprice.csv data for this method
Load Libraries:

Read Data
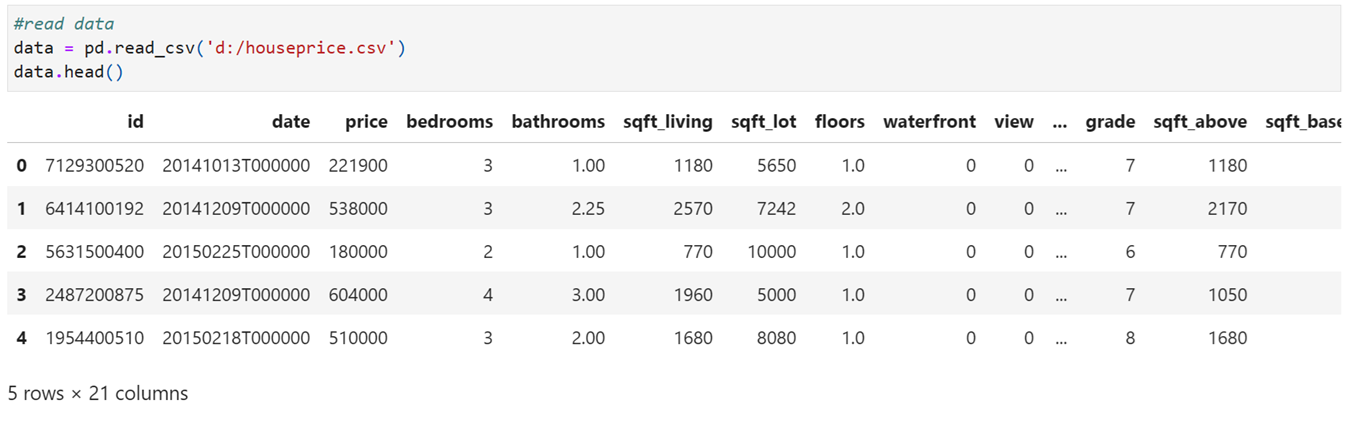
contains 20 features and one target variable (price)
Separate features and target variables

Split data into training and test data

Training data set will contain 70% and test data size will contain 30% of the data
Know the shape of train and test data

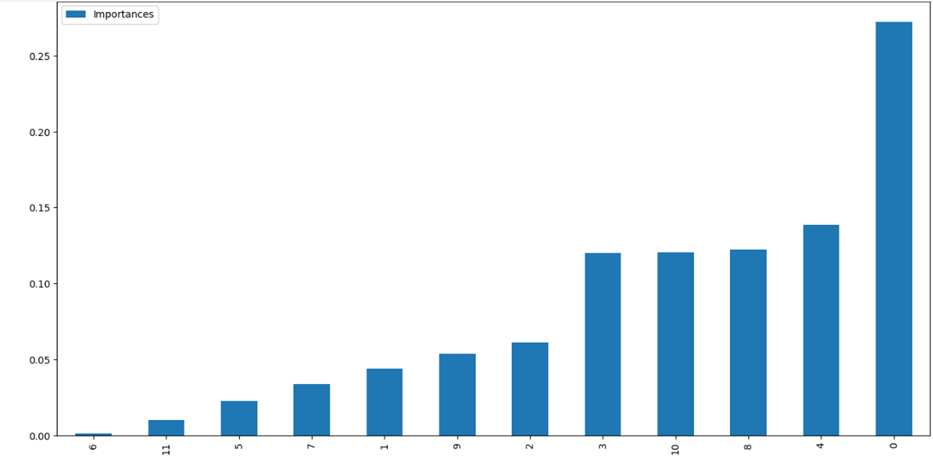
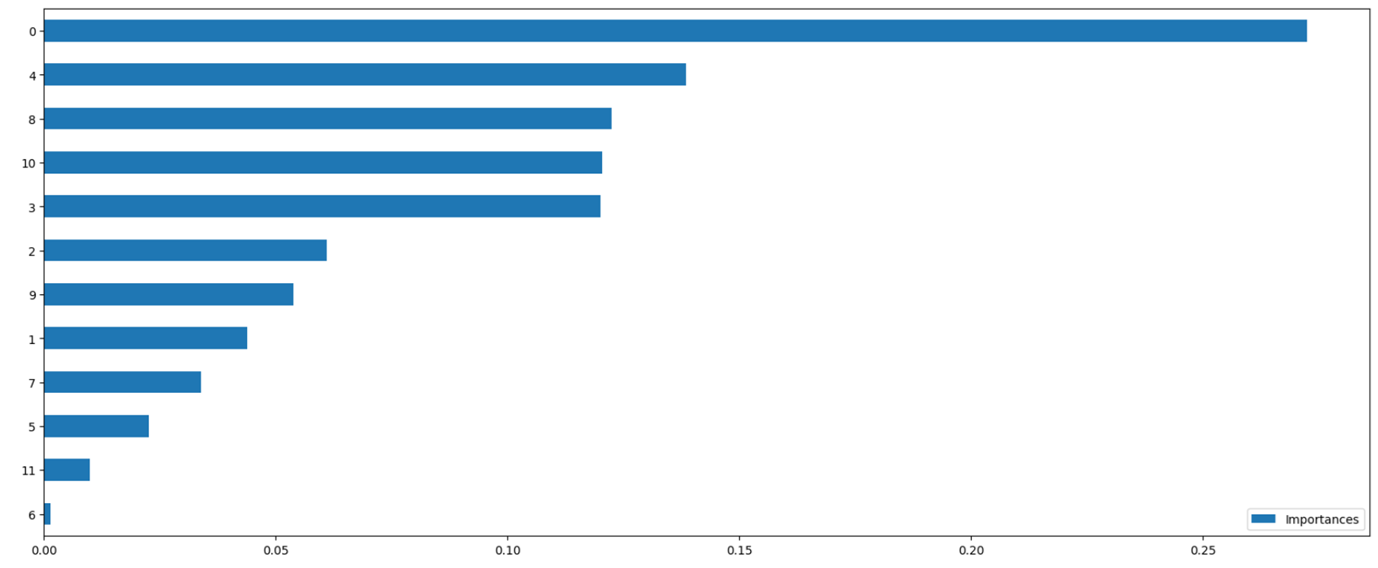
Find feature importances using Random Forest Classifier
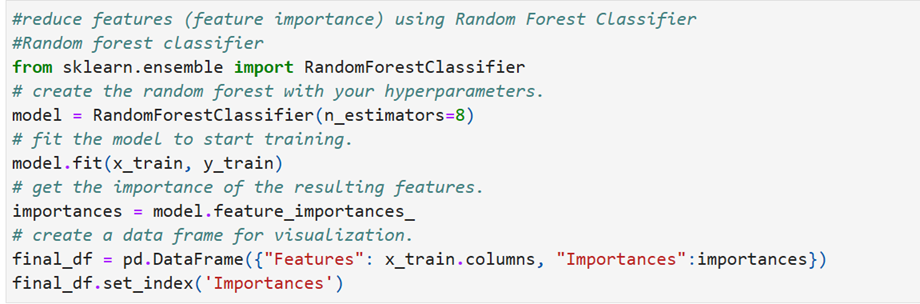
we want to restrict the features to 8. Assign 8 to n_estimators
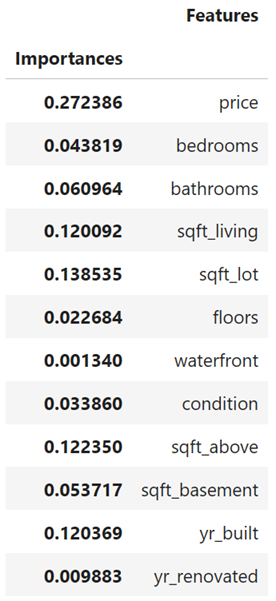
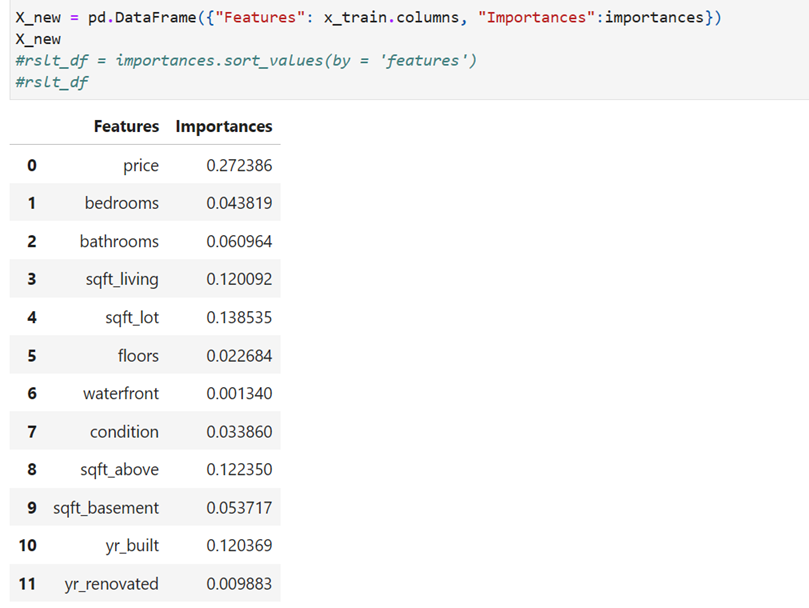
feature with index
Vertical Barplot

Horizontal BarPlot

Second Example:
Here we use custchurn.csv data
Load libraries:
Read data

Separate features and target

SequentialFeatureSelection Function
Sklearn.feature_selection contains sequential feature selector function. Forward selection technique starts with an empty set of features and iteratively add features that improve the model’s performance until no significant improvement is observed
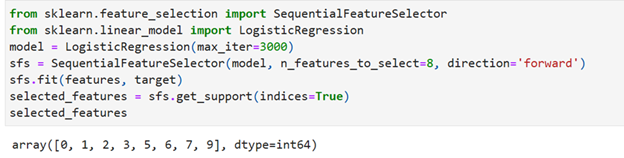
Under logistic regression you have to give max_iter = some huge number. Otherwise, you will get error stating that max_iteration limit exceeded. The arguments in SequentionFeatureSelector n_features_to_select must be less than 11 and the direction must be ‘forward’ for forward selection
Display selected features using a dataframe
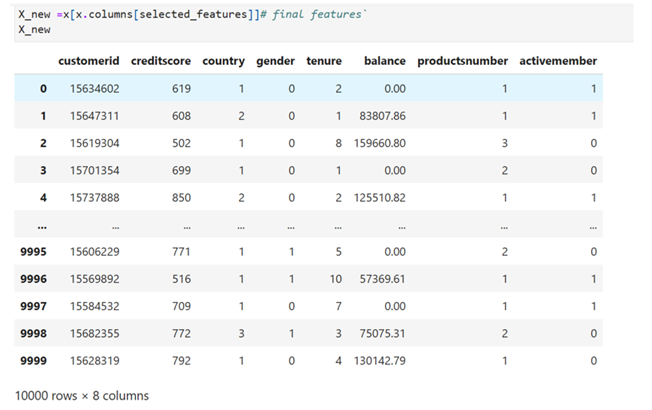
Using this technique we have reduced the features to 8 from 11 features and one target. Now the reduced features and target variables are ready for further analysis