
Initially all given features are included and then iteratively this technique removes all less important features from the dataset. System evaluates the performance of the model at each step till it finds the performance of the model starts degrading just because of the removal of further features
Load Libraries:

Here we use MH.csv
Read Data
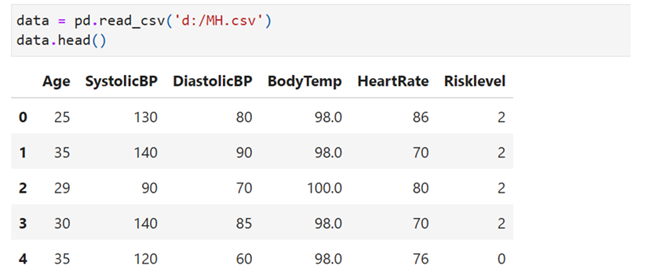
Separate features(independent) and target (dependent) variables:
Split the data into training and test data sets

Training dataset: Testing dataset ration = 70:30
Backward Elimination
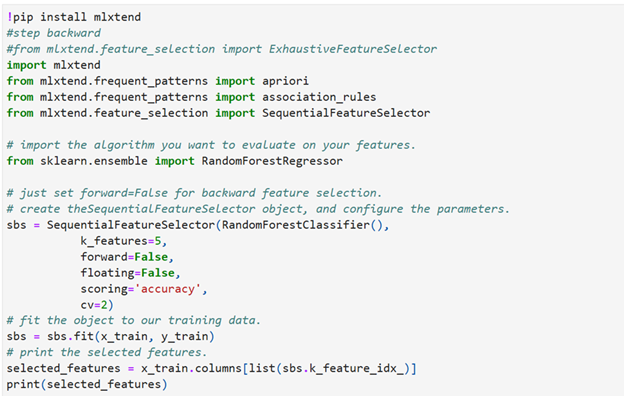
Install mlxtend module in python thro’ jupyter notebook
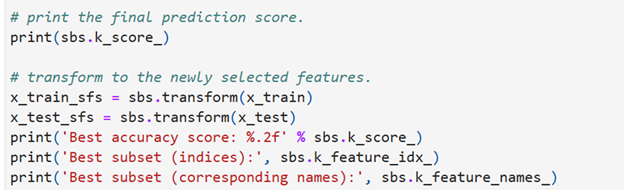
Output:

Here all the features have been selected based on the performance of the model. Now dataset is ready for further analysis