
Univariate Selection is one of the machine learning techniques that identifies the most important features in a dataset. You can view it as a preprocessing step to an estimator. Sklearn comes with a preprocessing routine that implements the transform method.
SelectKBestremoves all but the k highest scoring featuresSelectPercentileremoves all but a user-specified highest scoring percentage of features- using common univariate statistical tests for each feature: false positive rate
SelectFpr, false discovery rateSelectFdr, or family wise errorSelectFwe. GenericUnivariateSelectallows to perform univariate feature selection with a configurable strategy. This allows to select the best univariate selection strategy with hyper-parameter search estimator.
These objects take as input a scoring function that returns univariate scores and p-values (or only scores for SelectKBest and SelectPercentile):
- For regression:
r_regression,f_regression,mutual_info_regression - For classification:
chi2,f_classif,mutual_info_classif
Load libraries

Read Data

Find target variable

Target variable contains two classes: 1 Malignant and 2 Benign
Convert categorical values into numerical value using LabelEncoder


Separate features and targer variables:

Univariate feature selection using sklearn feature selection
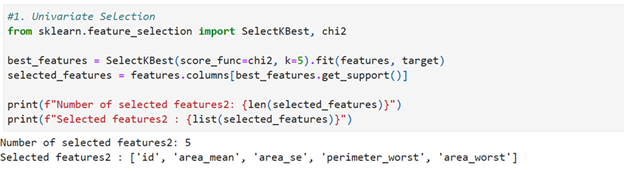
Out of 31 features system has selected best k (5) features
Accuracy of Logistic Regression Model after reduction
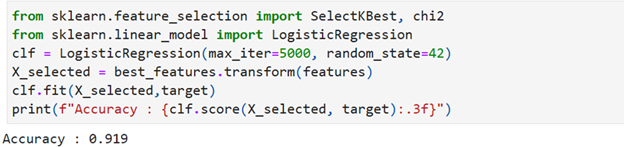
Accuracy of the model works out to 91.9%