Measures the amount of information obtained about one variable through another variable. It captures any kind of relationship (linear or non-linear) between the feature and the target. Effective for both classification and regression problems, and can handle both continuous and categorical data. Ex: In a health dataset, mutual information can help identify how much information the cigarette smoking (feature) provides about the likelihood of heart attack(target variable).
- Calculate the mutual information score between each feature and the target variable. 2.Compare the mutual information scores to a pre-defined threshold. 3.Select features with mutual information scores above the threshold.
Use mutual_info_classif function obtained from sklearn.feature_selection library. Threshold is fixed at 0.1. If mutual information scores of features are more than threshold value (0.1) then they are removed from the dataset
Let us use the same data what we used for Univariate feature selection
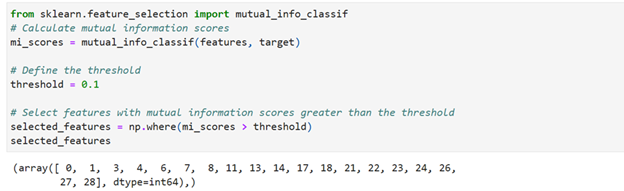
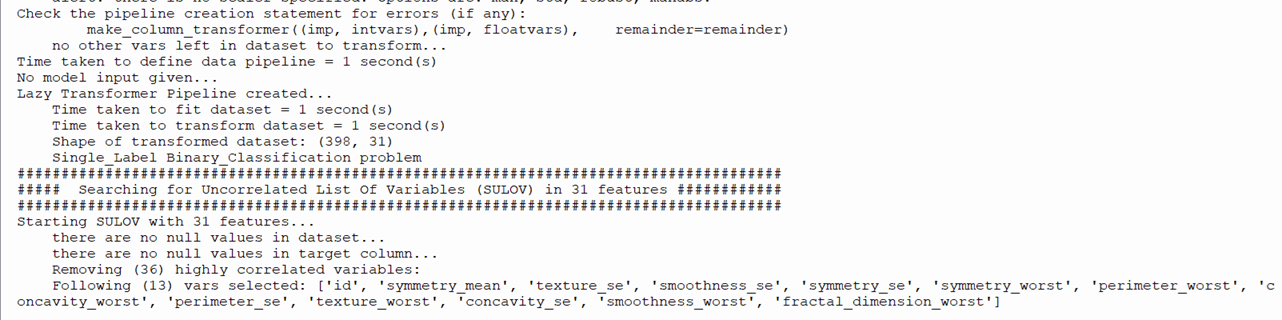
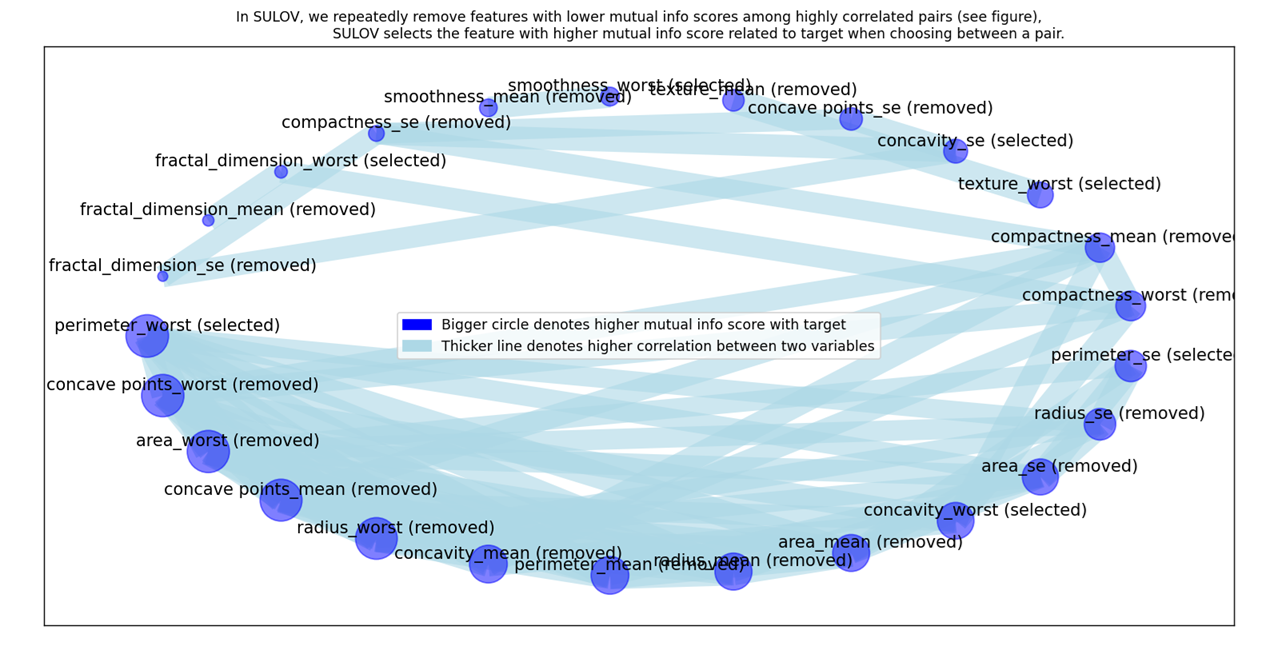
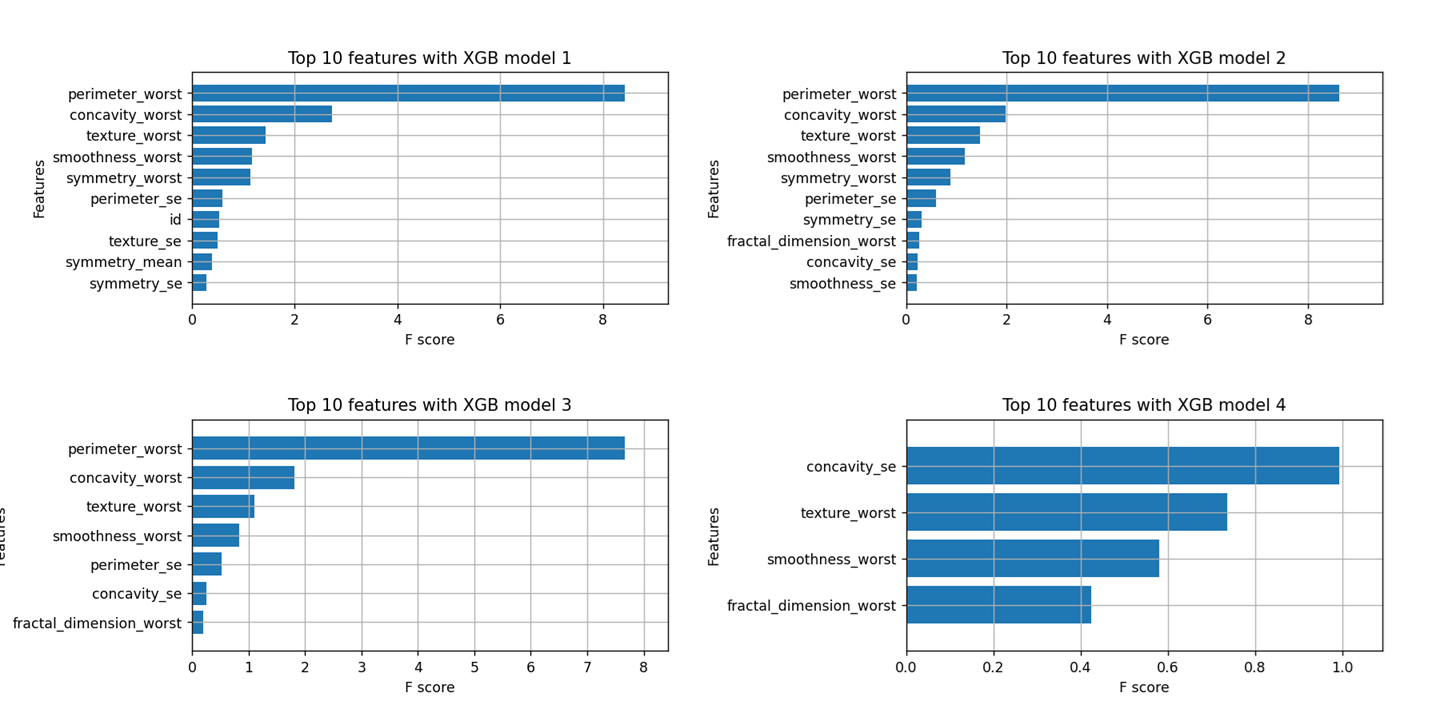
Under this technique 31 features have been reduced to 19 features. Now selected features are ready for further analysis.
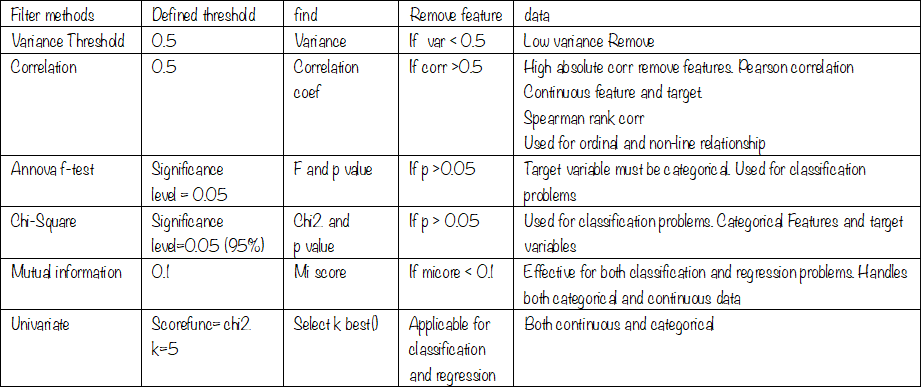
Summary Table
Using featurewiz (Lazy Transform)
Selection of relevant features for further analysis can be done using Lazy Transform method where we use featurewiz package
For installing featurewiz you must have python version. Thonny software is built on Python 3.10.11. Install package featurewiz and search through button PyPI.
import featurewiz as fw
import pandas as pd
data = pd.read_csv(‘d:/wdbc.csv’)
print(data.head())
data = pd.DataFrame(data)
X = data.drop([‘diagnosis’],axis=1)
y = data[‘diagnosis’]
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=42)
fw.featurewiz(data, target=’diagnosis’)
from featurewiz import FeatureWiz
fwiz = FeatureWiz(corr_limit=0.70, feature_engg=”, category_encoders=”, dask_xgboost_flag=False, nrows=None, verbose=2)
X_train_selected = fwiz.fit_transform(X_train, y_train)
X_test_selected = fwiz.transform(X_test)
### get list of selected features ###
fwiz.features
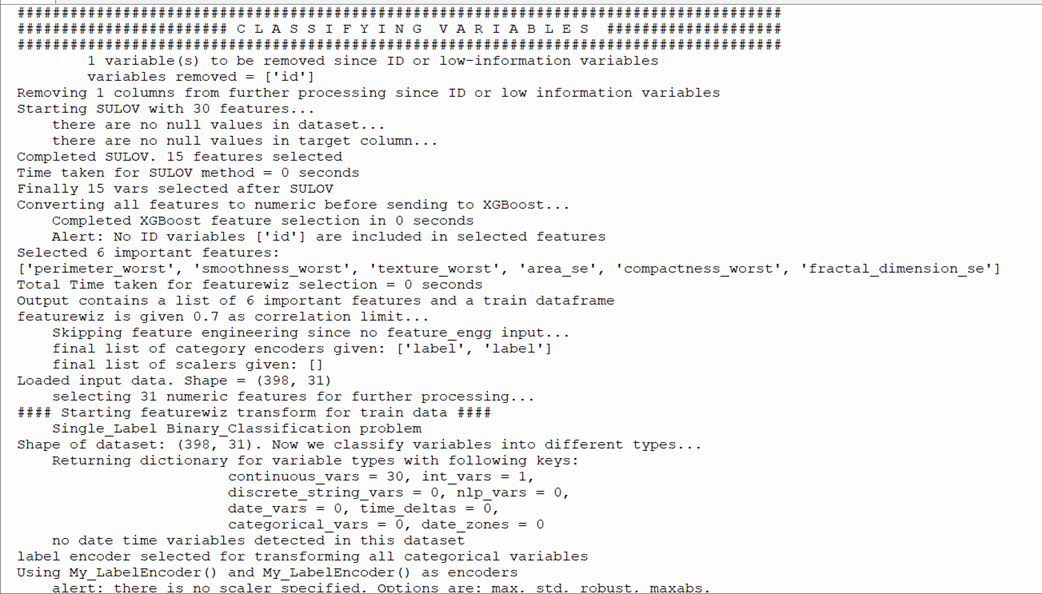
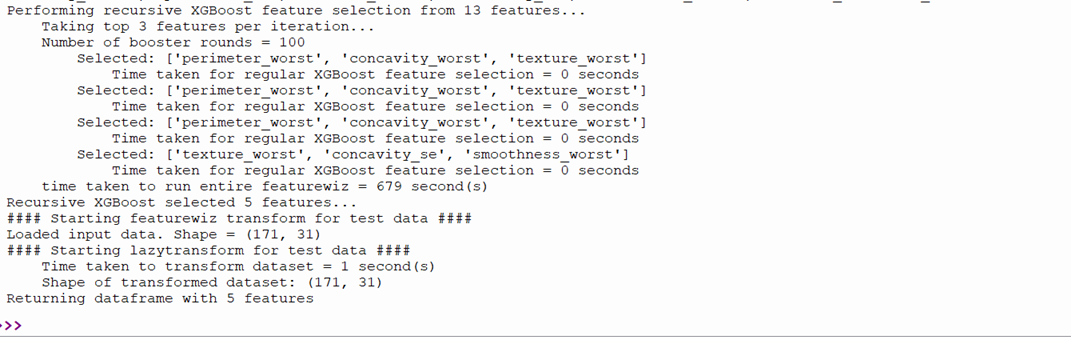
Run the program wdbc.py. Output