When Target Variable is Numerical:
Here the target variable is numerical. Previously we the target variable was categorical(both binary and multi class). Let us use the dataset obtained from Kaggle’s “Student Performance (Multiple Linear Regression)” dataset. This dataset contains one target variable (PerformIndex) and Hours studied, Previous scores, Extracurricular Activities, Sleeping Hours, Same Sample questions Practiced(5) independent variables. for our convenience sake we have changed the label of features and target

The performance index represents the student’s academic performance and has been rounded to the nearest integer.
The index ranges from 10 to 100, with higher values indicating better performance. The data contains 10000 records
Load libraries and read data
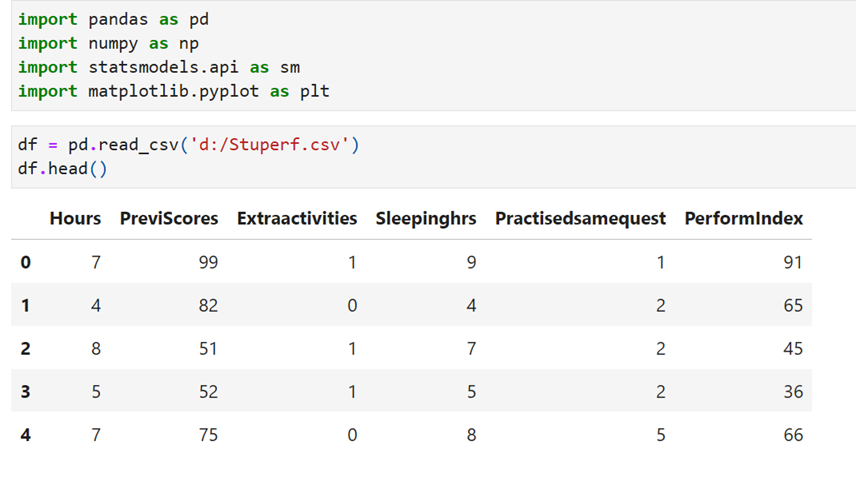
Information about data
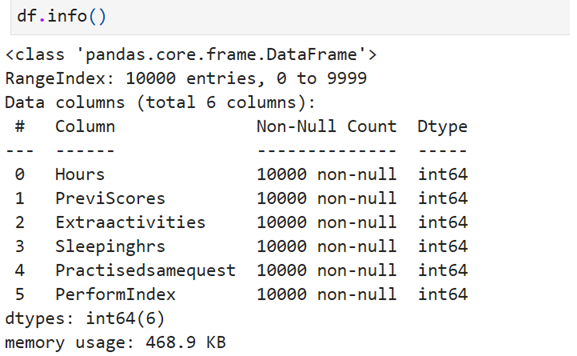
Statistical Information
Check if any null value exist?
Separate features(X) and target(y)
DecisionTreeRegressor: criterion-Mean Squared_error(mse)
Tree using Squared_error
Decision Tree using default-Squared_error criterion + mean value
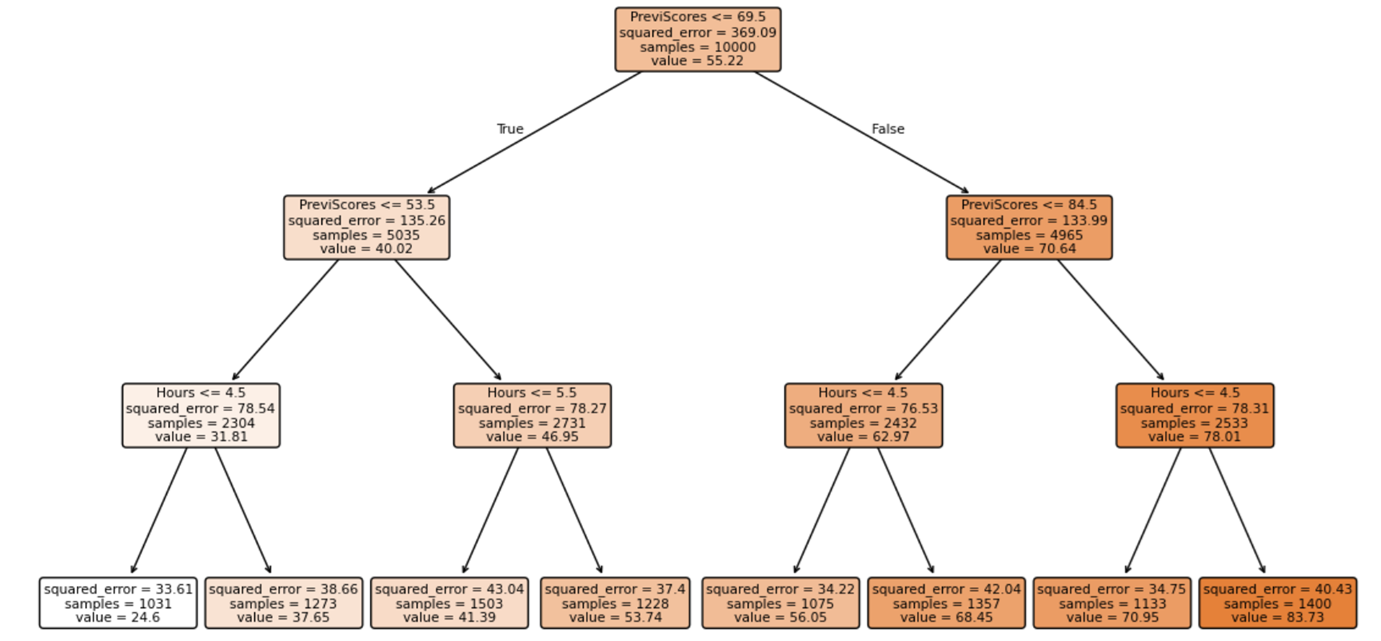
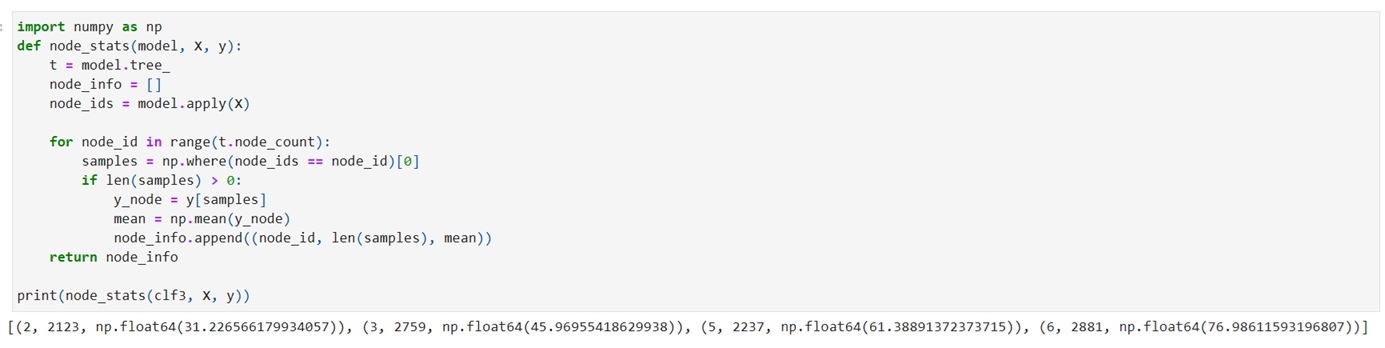
Node statistics

show the results after converting the array into DF
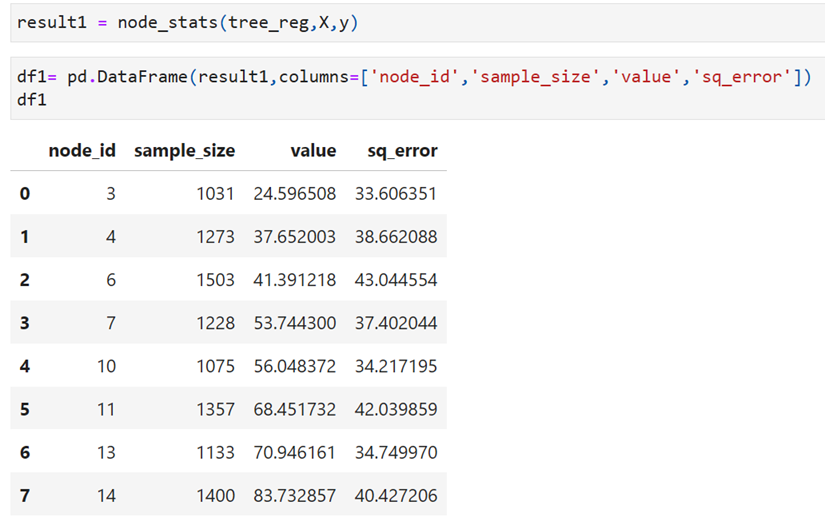
Result shows only the leave-less children nodes and their respective values
DecisionTreeRegressor: criterion-Mean Absolute_error(mae)
Decision Tree using Absolute-error Criterion
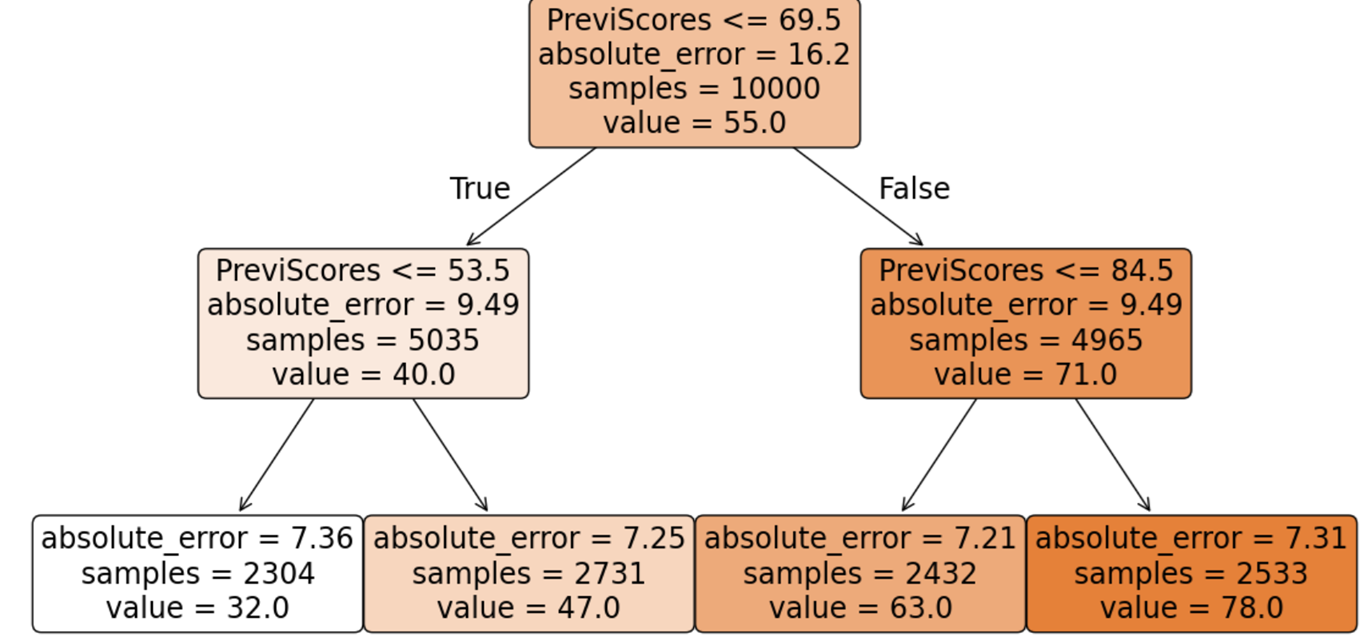
Tree Impurity

DecisionTreeRegressor: criterion-Friedman mse
Decision Tree using Friedman mse Criterion
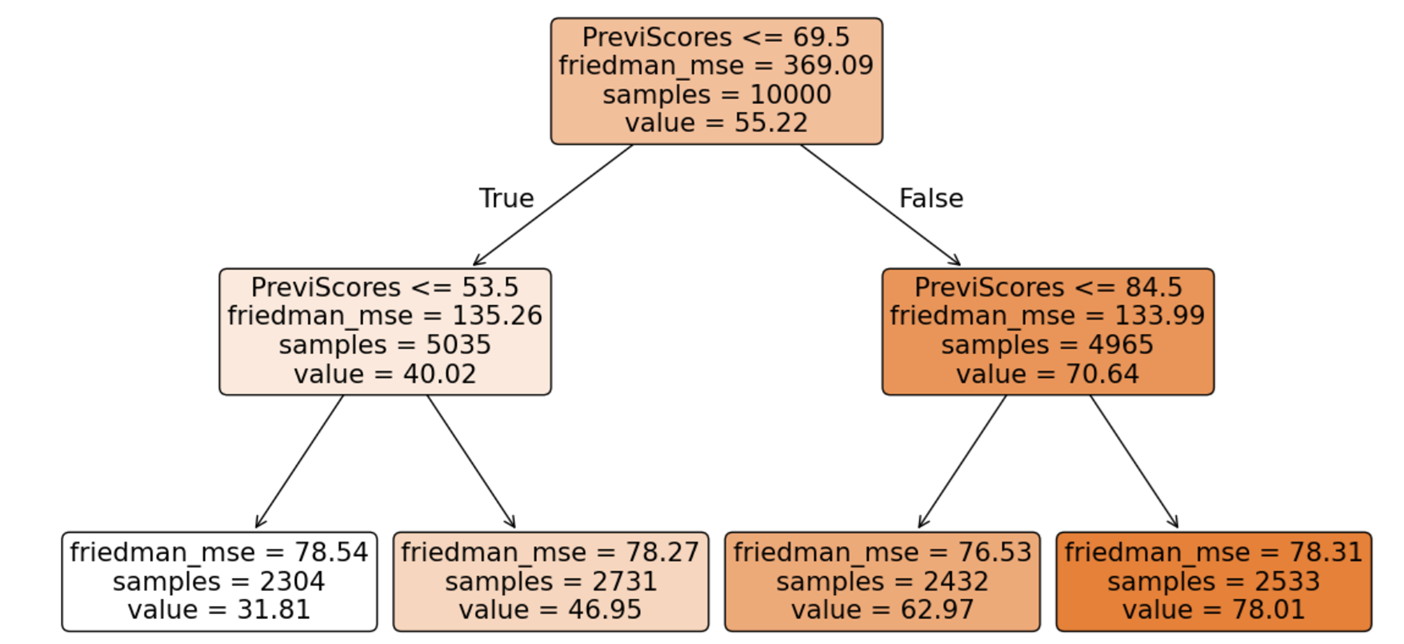
Tree Impurity

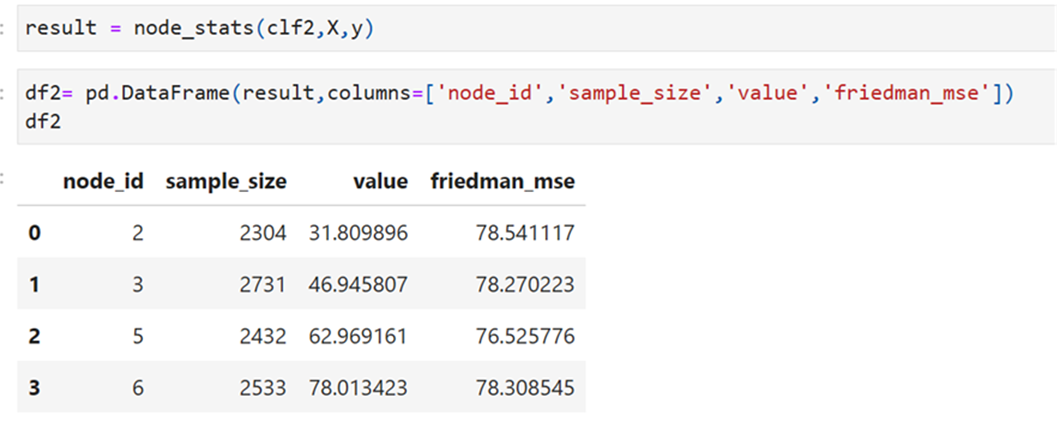
Node Statistics

show the results after converting the array into DF
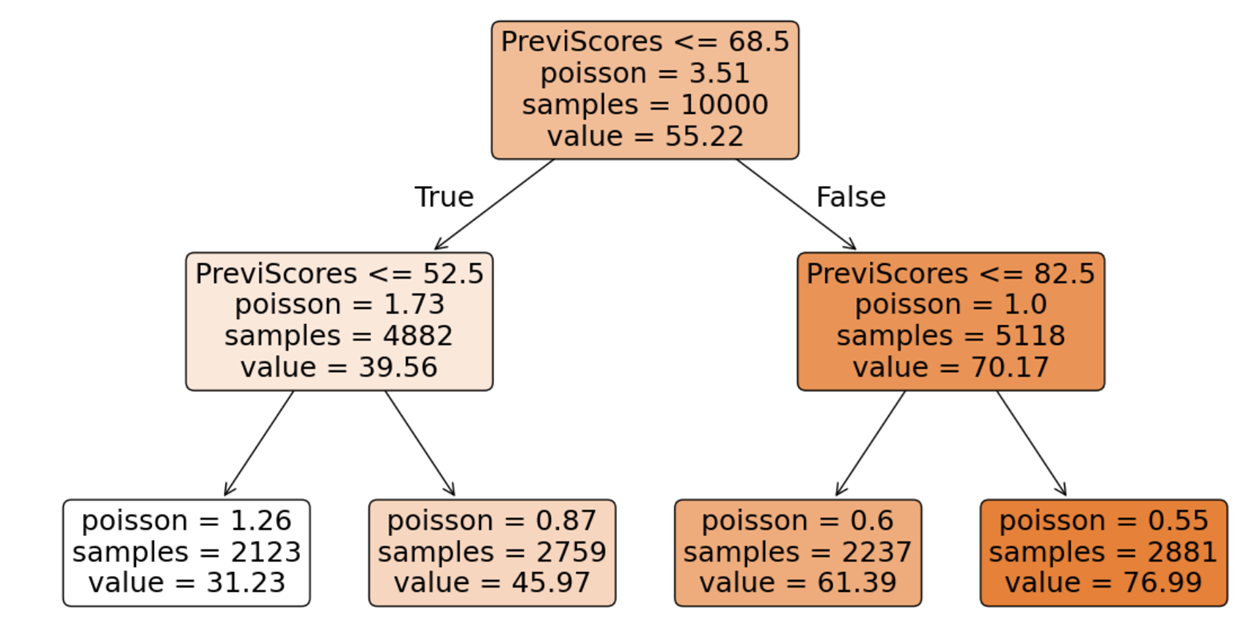
DecisionTreeRegressor: criterion-Poisson
Decision Tree using Poisson Criterion
Node Statistics

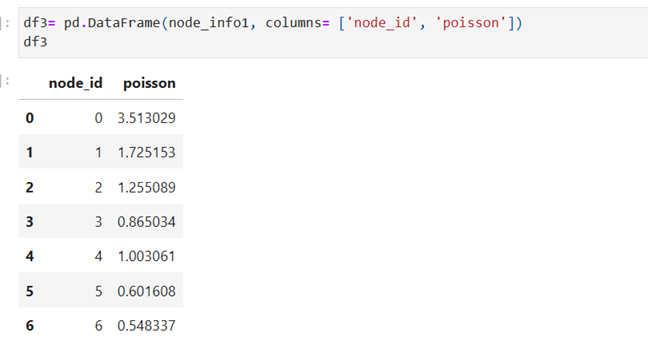
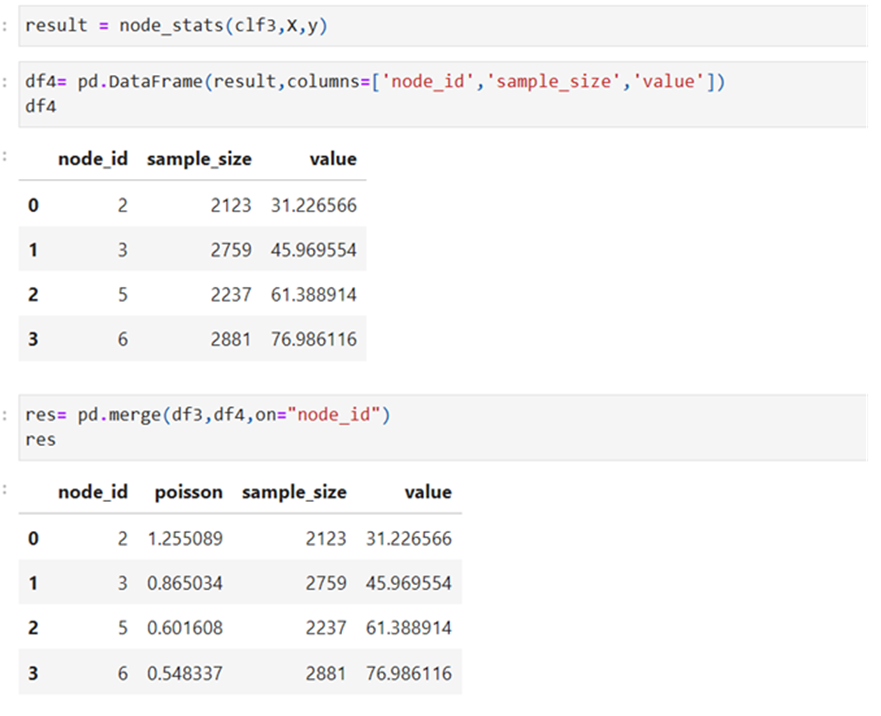
Make X and y as an array

Using Statsmodels’ find regression under OLS method

For the above we have already imported statsmodels.api as sm
Summary
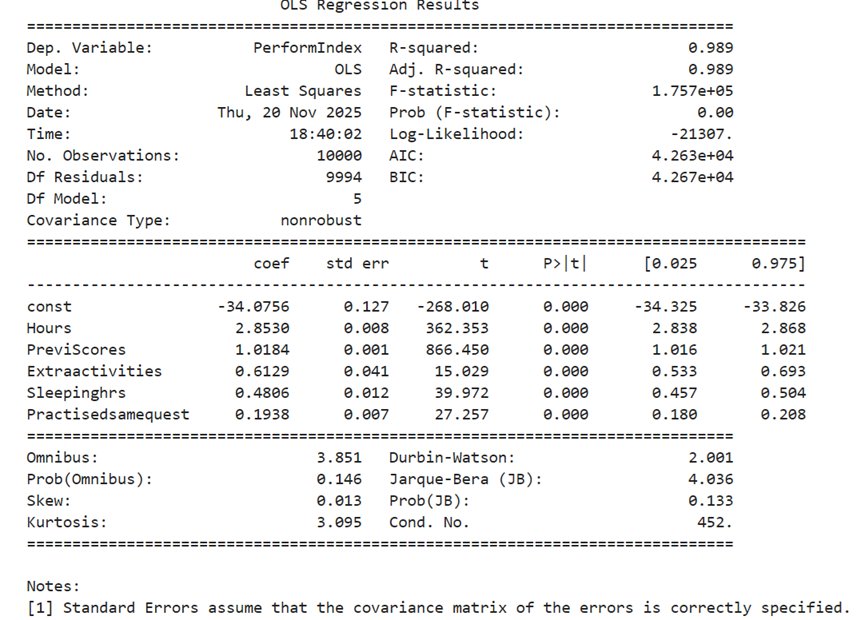
The formula for predicting Performance Index
yhat = -34.0756 +2.8530*Hours+1.0184*Previscores+0.6129*Extraactivities+0.4806*Sleepinghrs+0.1938*Practisedsamequest
Correlation
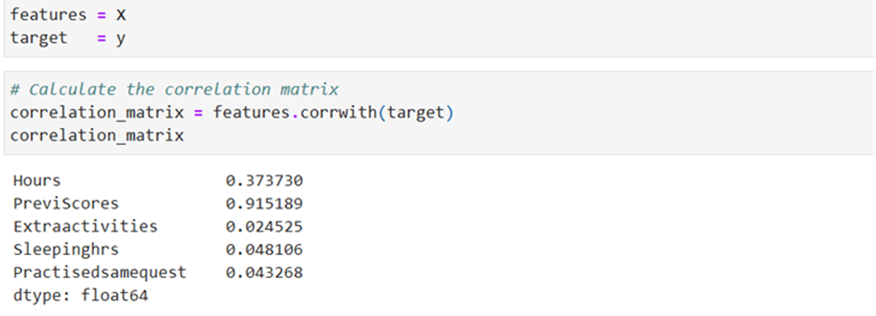
PreviousScores correlation is very high nearer to 1. So, if influences Performance Index in a more significant way than other features. the next high one is meant for Hours
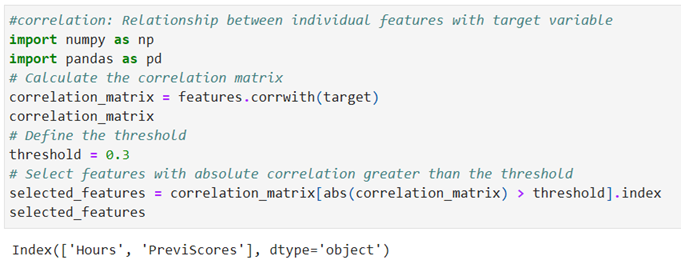
Feature selection Using Correlation
Feature selection Using CHI-SQUARE
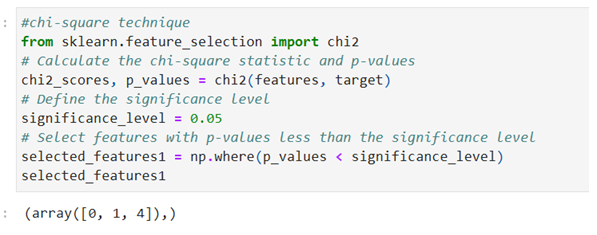
Selected features based on Chi-Square
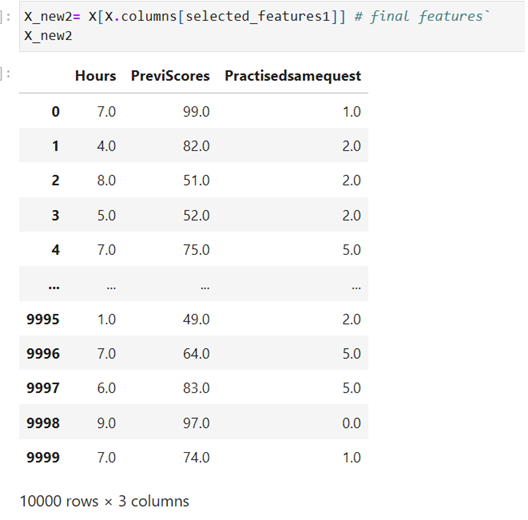
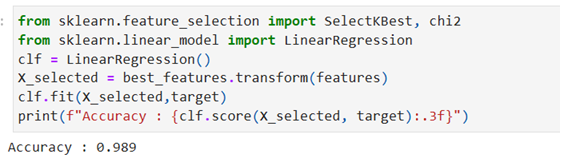
Feature Selection using Univariate, SelectKBest and chi2

Accuracy Using SKlearn