In order to improve the results of machine learning model we may include categorical coding as an important tool in Feature Engineering technology. Machine learning algorithm can understand numerical values for further mathematical processes and for the purpose of identifying pattern of the data. Before we hand over the data to the machine, it is advisable to convert the categorical features into numerical values just to boost the machine’s learning capacity.
Machine learning models always depend on numerical data. But we often include Categorical variables in our datasets. Categorical variables represent qualitative characteristics of the attribute we handle. We handle with categorical features like hair colors, nationality, models of the cars, type of products, states, education levels. These data cannot be used directly as we do use the numerical data. Machine learning algorithms are designed to handle numerical data only. So, we transform the categorical data into numerical form. This process is called Categorical encoding. Let us examine the two commonly used encoders for the transformation of categorical data into numerical values.
- Label encoding
- One-hot encoding
Besides the above we have the following available encoders in Python
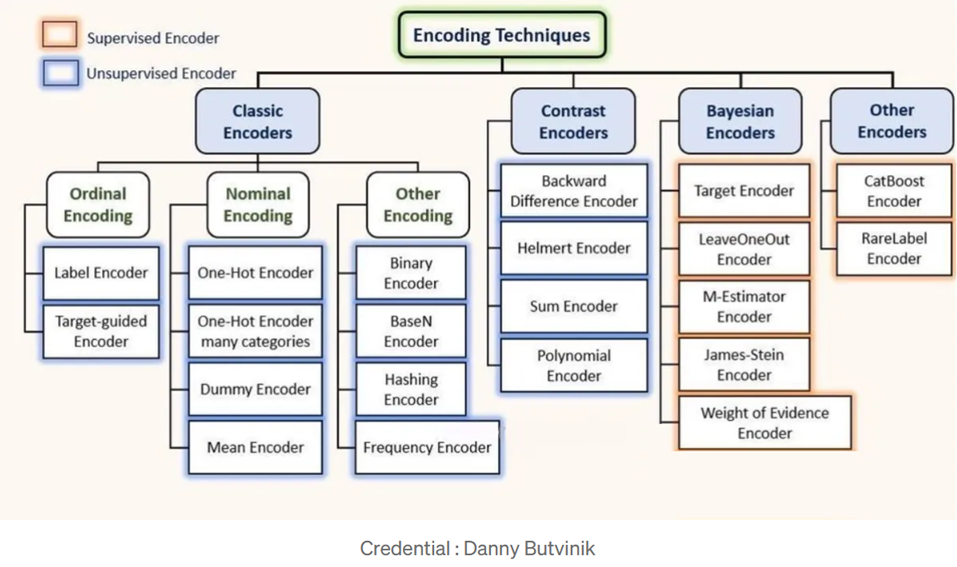
- LabelEncoder } Classical encoder for Ordinal Categorical features
- OneHotEncoder } Most commonly used encoders – Classical But meant for Nominal Categorical features
- OrdinalEncoder } Classical meant for Ordinal categorical features
- TargetEncoder } Bayesian Encoder based on the target mean value
- BinaryEncoder } Classical Encoders – coming under other encoder methods
- HashingEncoder } Classical Encoders – coming under other encoder methods
- FrequencyEncoder } Classical Encoders – coming under other encoder methods
- LeaveOneOutEncoder } Bayesian Encoder Similar to target encoder but in a different way
- PolynomialEncoder } Contrast encoder
- BackwardDifferenceEncoder } Contrast encoder
Main Issue:
Handling of categorical data is somewhat difficult when the number of categories is large. Algorithm expects numerical values. Categorical data can be interpreted as ordinal or numerical values. When we do this the performance and accuracy of the model will be affected.
Categorical Coding: This is the process of converting categorical data into numerical values. 90% of the work is done with the first two encoding methods. Others are used in very specific cases.
MOST COMMONLY USED CATEGORICAL FEATURE ENCODERS
1. Label Encoding:
This method assigns a unique integer value to each category. Say we have one dependent variable (y)- CustChurn contains two categories Yes or No. Since categories are shown as string variable machine learning model cannot use this. Categories have to be converted as 1 or 0. Here there is no order/rank. Another example Size of banian is a categorical feature contains three categories
- Small
- Medium
- Large
Here the categories have an inherent order or rank. So, size is to be converted as
Small 1
Medium 2
Large 3
And not as small as 3, large as 2 and medium as 1
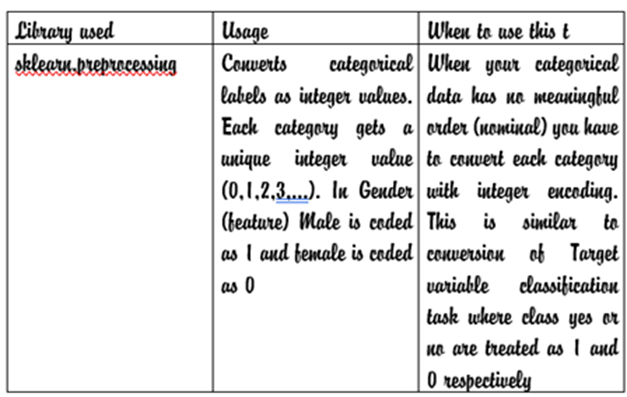
- Label encoding is generally used when the categorical variable has an ordinal relationship(i.e., the categories have an inherent ranking, such as [Low, Medium, High]). In this case, the numeric encoding preserves the order.
- Use Label Encoding cautiously for nominal (unordered) variables, as it can introduce a false sense of order.
Label encoding Using sklearn.preprocessing
Load libraries
Read data
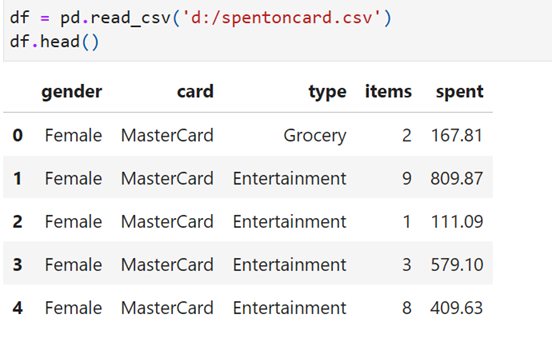
Here gender, card,type are categorical features. Straigth-a-way these can not be used to predict spent amount(y -dependent variable). these items have to be converted to numerical values using Lebal Encoder
find info()
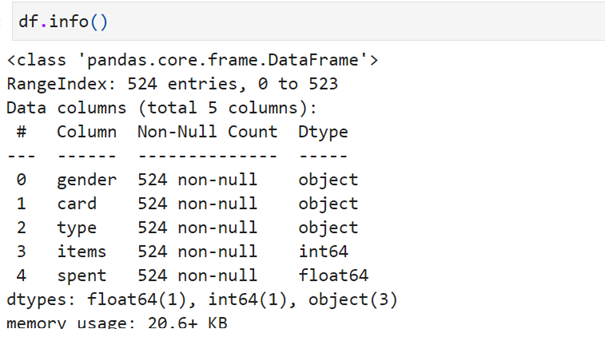
See categorical feature type are defined as object. Not suitable for further analysis
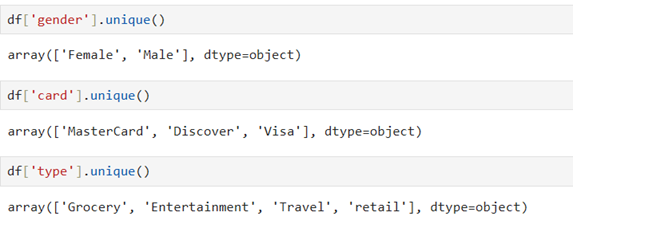
Categorical features contain the different type of classes:
Use object.unique() to know the classes in each feature
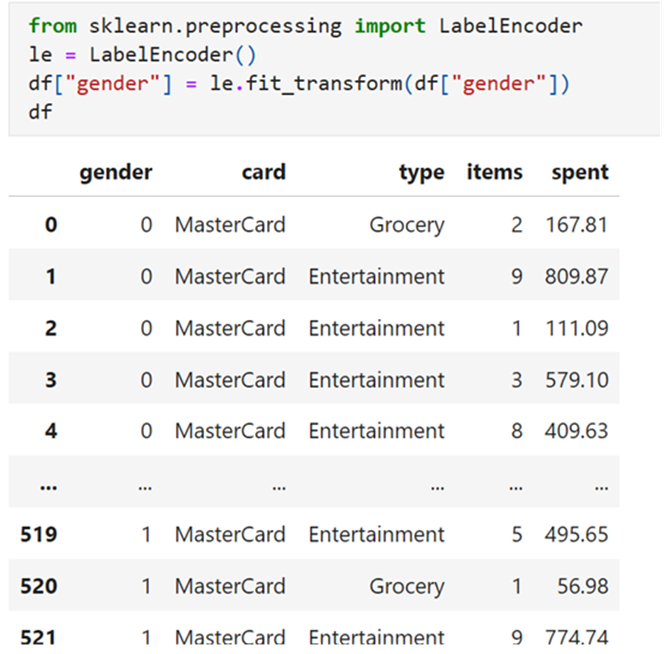
convert gender into numerical value (male-1 and female -0) using Label Encoder
convert card feature in numerical classes
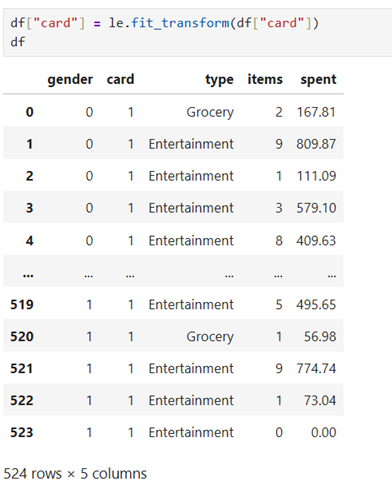
convert type feature into numerical classes
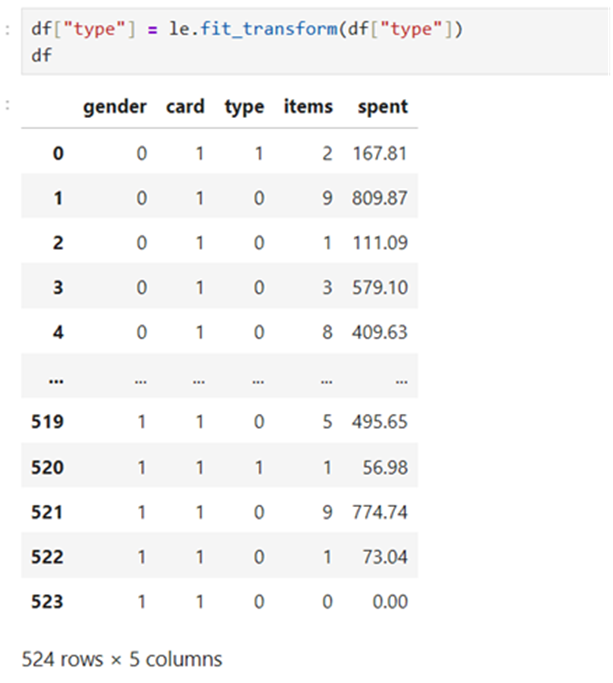
Now all features have been encoded with numerical values. Now we shall proceed for further analysis using statsmodels.api
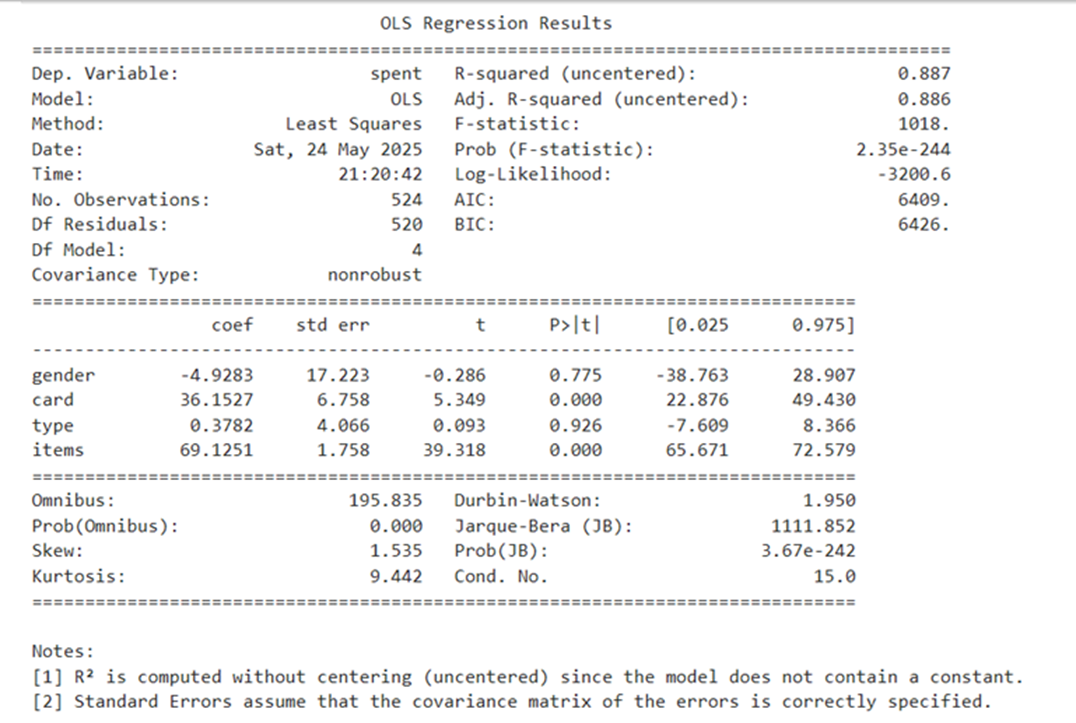
Summary:
Adding Constant :

Summary after addition of constant
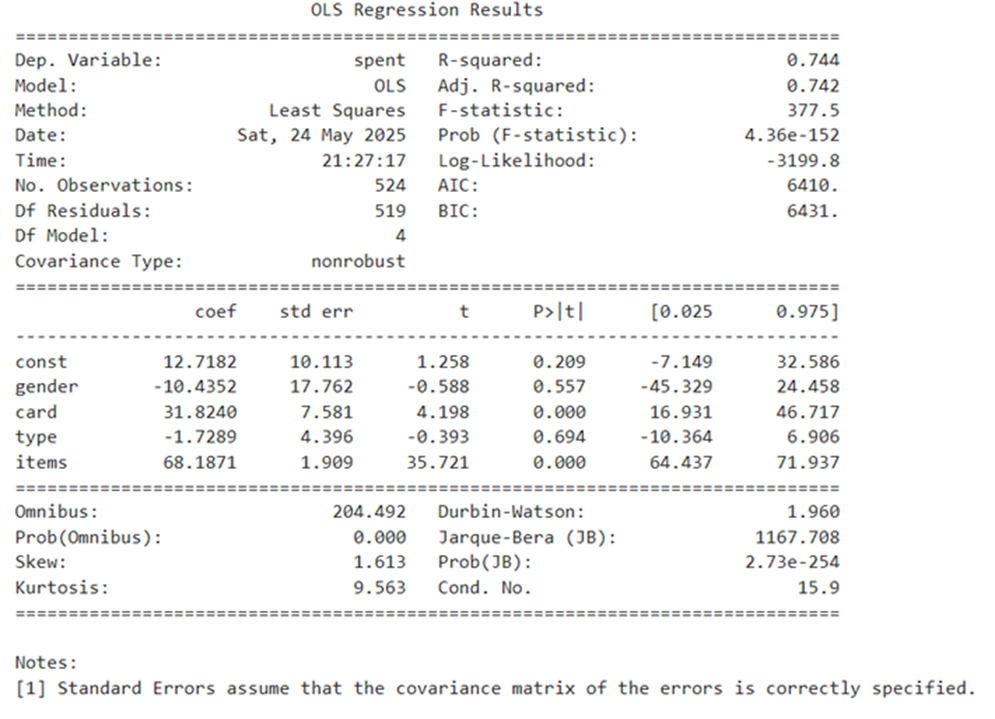
Yhat = 12.7182- 10.4352*gender+31.8240*card-1.7289*type + 68.1871*items
2. One-Hot Encoding using Pandas pd.get_dummies()
This method converts each category into a new binary column (or feature). Each column corresponds to a single category, marked as one if the category is present and 0 otherwise, suitable for nominal variables.
- One-hot encoding is preferred for nominal (unordered) variables (e.g., gender, country, or color). This method avoids introducing false ordinal relationships.
- The trade-off is that One-Hot Encoding can dramatically increase the dimensionality of your dataset, especially when you have many unique categories.
- Disadvantage : Potential dimensionality curse
- One-Hot Encoding works well for datasets with a small number of unique categories. Still, it can drastically increase the dimensionality of your data when applied to columns with many unique values, making your model more prone to overfitting or computationally expensive to train
- If you are having 20000 unique categories for a feature one-hot encoding would generate 20000 additional columns. In that case use Target encoding (advanced)
Load libraries
Read data
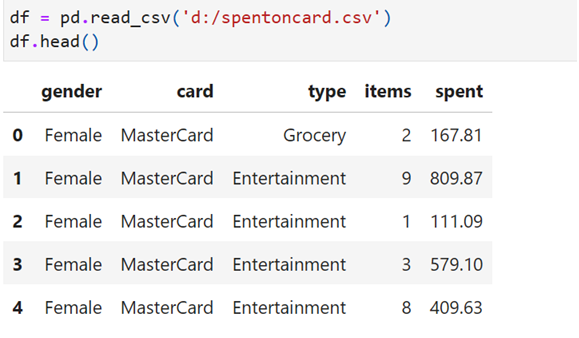
Find classes of each Categorical features
Encode the category classes for all features (categorical) with single function using pandas
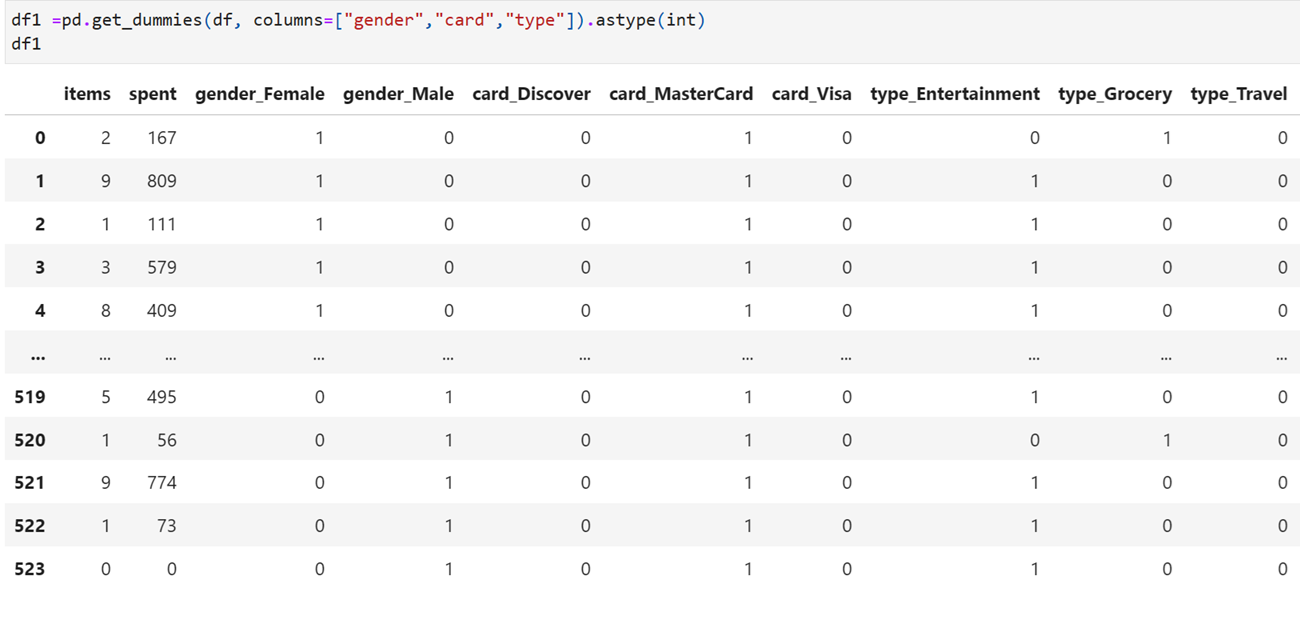

pd.get_dummies() creates a separate column for each category class with feature prefix. So it increases the feature numbers. Originally we had four features and one dependent variable “spent”. After using get_dummies() we get 10 features and one dependent variable. If categorical features contain many number of classes/category then it will increases the number of features.
Ananlysis using 11 columns:

summary
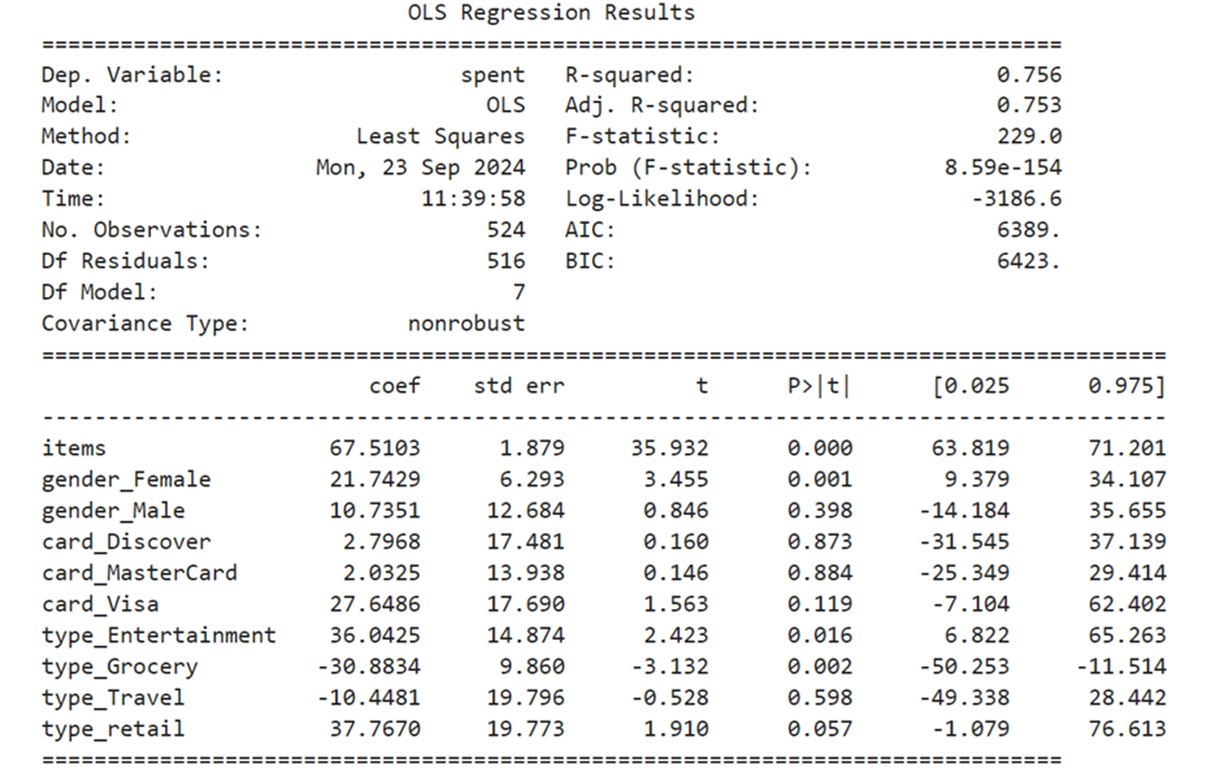

Add constant
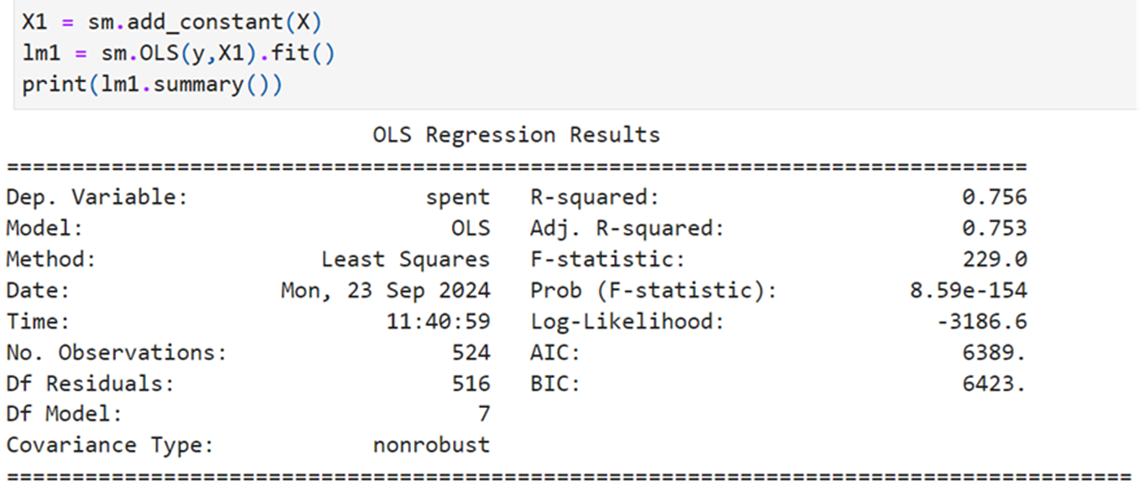
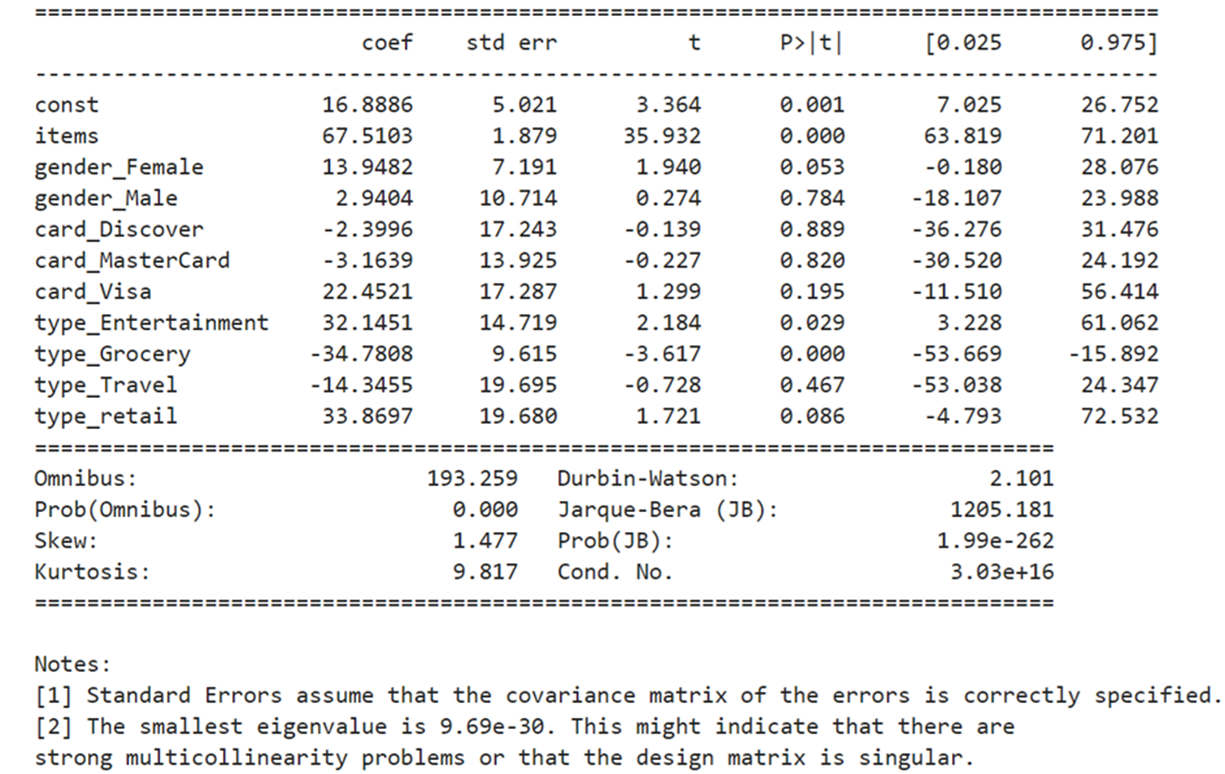
Using SKLEARN
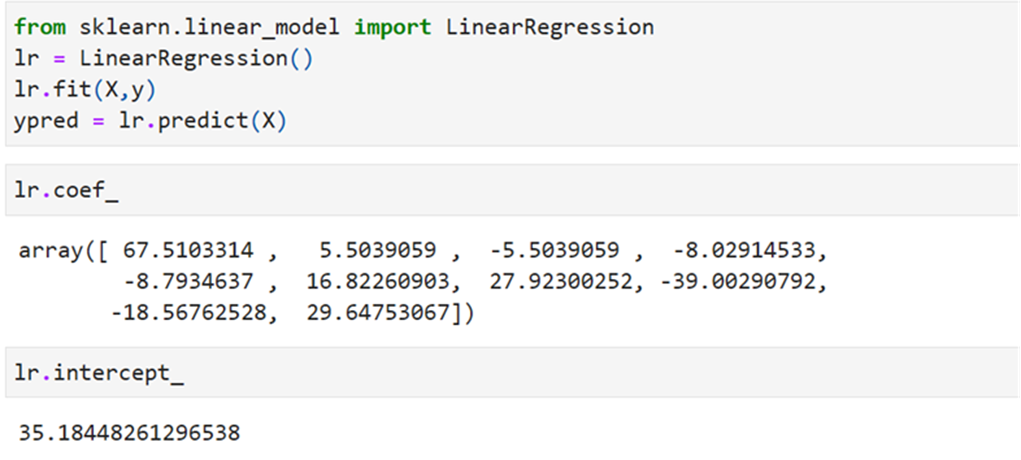
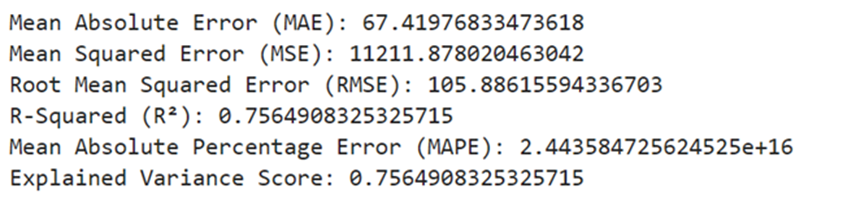
Metrics: