Random Forest Classifier
Embedded method: Feature selection is integrated or built into classifier algorithm. During the training step, the classifier adjusts its internal parameters and determines the appropriate weights/importance given for each feature to produce the best classification accuracy.
Load Libraries

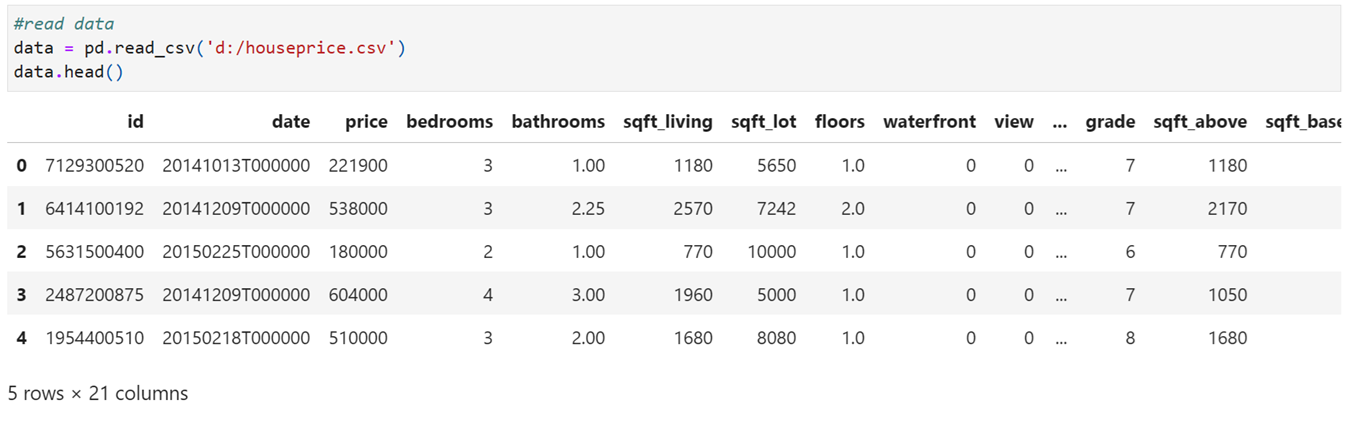
Read Data
Drop unwanted features and separate features and target

Split data into train and test dataset

Find shape of train and test datasets

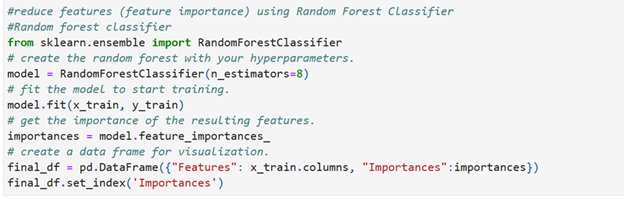
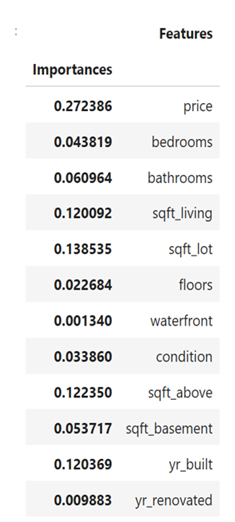
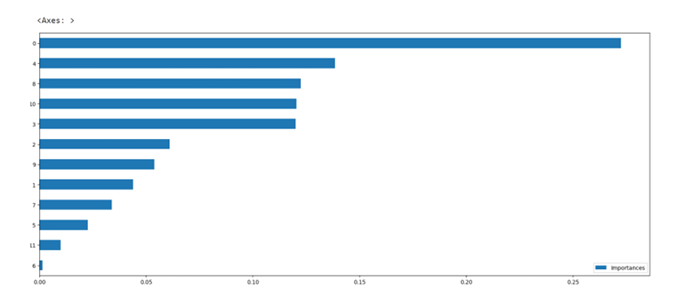
Random Forest Classifier Script

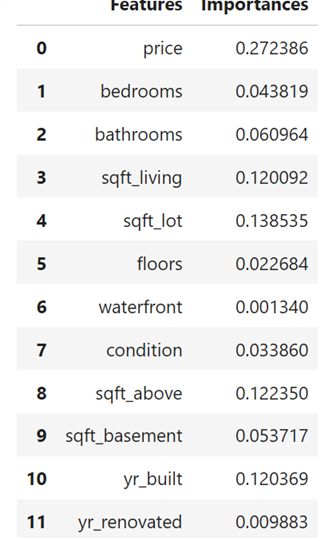
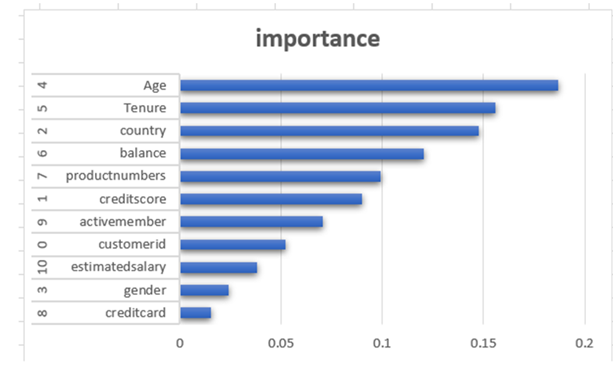
Horizontal bar plot

Gradient Boosting Machines(GBMs)- Gradient Boosting Classifier:
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.ensemble import GradientBoostingClassifier
df= pd.read_csv(‘d:/custchurn.csv’)
df.head(3)
features = df.drop([‘churn’],axis=1)
target = df[‘churn’]
X = features
y = target
# Generate a synthetic dataset
X, y = make_classification(n_samples=1000, n_features=11, n_informative=9, n_redundant=2, random_state=42)
# Create a Gradient Boosting model
model = GradientBoostingClassifier(n_estimators=100, random_state=42)
# Fit the model to the data
model.fit(X, y)
# Get feature importances
feature_importances = model.feature_importances_
# Create a DataFrame to display feature importances
feature_names = [f’Feature {i}’ for i in range(X.shape[1])]
importance_df = pd.DataFrame({‘Feature’: feature_names, ‘Importance’: feature_importances})
# Sort features by importance
importance_df = importance_df.sort_values(by=’Importance’, ascending=False)
# Display the feature importances
print(importance_df)
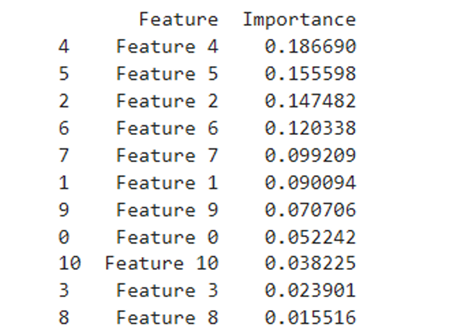
Importance(Relevant Features)