
Normalization/Standardization based on Distribution:
1. Z-Score Normalization:
- It is a data pre-processing technique.
- It transforms the feature values with mean as 0 and standard deviation as 1
- Achieved by centering data around the mean and scaling it based on the feature’s standard deviation
- This technique is used only when the algorithm assumes the data is normally distributed
- It is is less affected by outliers
- Use when your features are normally distributed and your algorithm points to Linear Regression, Logistic Regression and Support Vector Machines
Here we convert the normal variate X into Standard Normal Variate Z using the formula
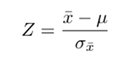
Each normal variate X is converted to Z
Function used for this Normalization technique
def z_score_standardization(series):
return (series – series.mean())/(series.std())
Then call this function using your independent features after dropping dependent variable feature
2.Robust Scaling
When you deal with datasets having more outliers you can convert the normal variate X using the formula
Robust_scaled_feature = (X – median(X))/IQR
We use median and IQR for robust scaling of X
Median and IQR are not affected by outliers. So it is robust
Usage
Use this method when your data contains many outliers, and you don’t want these outliers to influence the scale of your data
Function used:
def robust_scale(series):
#find median
median = series.median()
IQR = series.quantile(0.75) -series.quantile(0.25)
return ((series – median)/IQR)
You call this function with your data feature
3. Quantile Transformation:
Quantile Transformation maps the data to a uniform distribution and can also map to a normal distribution. It spreads out the most frequent values
and reduces the impact of outliers.
Usage: when you want to normalize the feature distribution to a uniform or normal distribution. This technique is useful when you deal with skewed data features
Function used:
def quantile_transform(data):
# Sort the data and compute the rank of each value
sorted_data = np.sort(data) # sort the given data using numpy
ranks = np.argsort(np.argsort(data))
quantiles = (ranks + 1) / (len(data) + 1)
return quantiles
Then call the function using your required feature data
Summary:

Practical Advice:
- If your model is distance-based (KNN, SVM, clustering) → scaling is critical.
- If your model is tree-based (RF, GBM, XGBoost) → scaling usually not required, but quantile normalization can sometimes help.
- If your data has outliers → prefer Robust Scaling.
- If you want probabilistic Gaussian-like input → use Z-score normalization.
- If features are on wildly different distributions → use Quantile Normalization.
Thumb Rule:
- Use Z-score when data looks roughly normal.
- Use Robust when outliers are present.
- Use Quantile when distributions are very different or highly skewed.
- If using tree-based models only, you often don’t need scaling.