We have been dealing with different machine learning models. The aim of model building is to predict the value of target variable(dependent) based on feature values. If we have only one feature (independent/explanatory) variable we use Simple Linear Regression model. If not (that is more than one feature) we use Multiple Linear Regression model. Feature variables can be grouped together and call X random variables which are independent of each other. Before go into the subject matter of Feature engineering let us understand the difference between inference and prediction. Under statistics we have already seen descriptive and inferential statistics.
Inference
Under Inference, we focus on understanding and explaining the relationships between the target and feature variables. We use Correlation Coefficient measure for this. The relationship could be either positive or negative or zero(no relationship). If the relationship is positive then it means the target values increases when indepdent variable increases in the positive direction(upward). If the relationship is negative, it is called downward relationship where target value either increases or decreases when independent value decreases or increases. (That is in the opposite direction). Generally we ask “why” and “how” the relationship between target and indepedent variable behave.
Prediction
Under prediction, we focus our attention to accurate forecasting outcomes for new or test datasets/data points. It is concerned with “what will happen” when one unit of independent variable changes (increase or decrease). We use complex models to achieve high degree of accuracy even if the models we propose are harder to interpret.
While constructing models we have to consider the following two aspects, Accuracy and interpretability, irrespective of the fact whether the model is simple or complex. Simple model is easy to interpret and it is less prone to overfitting. However, complex models are prone to overfitting. We can not compromise Accuracy for the sake of simplicity. The key consideration of a model building lies on fine Trade-off between accuracy and interpretabililty. Additional parameters play critical role in getting the accuracy and interpretability aspects in the right mix.
Feature Engineering:
Feature engineering is nothing but a process of creating representations of data that increases the effectiveness of the model
- Some models can not tolerate predictors(features) that measure the same underlying quantity(multi collinearity or correlation between independent features). The beauty is that two or more independent variables may be highly correlated with each other. it may miss lead to wrong prediction of y value.
- Missing values may lead wrong prediction. So data preprocessing is required to remove missing values or subsitute missing values
- Irrelvant predictors(features) available in the data may confuse and provide wrong prediction.
Feature Engineering and Variable (feature) Selection will solve this type of problems. Dimensionality Reduction or reduction of feature enables you to maintain the simplicity and interpretablity.
Why Feature Selection plays vital role in model building?
- Curse of Dimensionality: When we deal with huge number of features we suffer from different issues which may complicate out data analysis and machine learning tasks. The sparsity of data points may prevent you to find meaningful patterns and relationships. Dimensionality reduction provides simplicity.
- Computational Complexity: When dimensality increases we may require high computational storage, process and analysis. Algorithm may be lengthy and unexplainable at one stage and it may be explensive also
- Interpretability: Complexity of the model prevent you to have the easy interpretability characteristics. High-dimensional models are to prone to capture noise. Overfitted models are complex in nature. You may not be able to judge which features are influential.
- Distance Matrix: This one works well with low dimenstional data. In high-dimensional data it may lose its interpretive power. You may not be able to explain why certain data points are considered and others are not considered.
Feature Selection Methods:
- Filter based
- Wrapper methods
- Embedded Techniques
- Hybrid Techiniques
Filter Based Techniques:
Here we use statistical measures for evaluating and ranking features independently.
- Provide a dataset containing labled columns(exploratory variables) or dependent variable
- Assess the feature importance using a single statistical measure (metric) like variance threshold, correlation, annova f-test, chi-square, and mutual information
- Based on chosen metric system calculates a score for each feature column
- Features are ranked by their scores, with the best-performing ones at the top. Decending order
1.VARIANCE THRESHOLD:
This technique removes all features whose variance does meet the specified threshold condition. Features with very low Variance or constant variance do not carry much information. Under pre-processing process this technique enables you to remove features which are not giving any valuable information for model analysis. In a dataset where one feature is mostly constant (e.g., almost all values are 1), a variance threshold can remove this feature before further analysis. Workflow:
- Calculate variance of each feature
- Compare the variance of each feature to a specified threshold
- Remove the features with variance which fall below the threshold value specified
Python:
Let us use the data available in Kaggle Breast Cancer Wisconsin (Diagnostic) Data Set and reduce the features available. This dataset contains one target/dependent variable and 31 features(independent/explanatory variables)
Load Libraries and read data
Find shape of the data
Shape of the data: Contains 569 records and each record contains 32 features

our aim is to select relevant features so as to avoid irrelevant features which do not contribute info
Split the data into training set and testing set

training set : 70% and test set is 30%.
convert the training data set related to exogenous/explanatory variables into numeric using numpy

Use variance threshold library with threshold = 0.5
Based on the condition the features are reduced to 11. Supported features

Selected Features out oringinal features 31+ 1(dependent variable)

It means based variance on threshold conditions we can remove the irrelevant features (20) which do not contribute much information. Let us select the selected features and placed in dataframe df2
df2 = pd.DataFrame(data, columns=[‘id’, ‘radius_mean’, ‘texture_mean’, ‘perimeter_mean’,
‘area_mean’, ‘perimeter_se’, ‘area_se’, ‘radius_worst’, ‘texture_worst’,
‘perimeter_worst’, ‘area_worst’]) print(df2) x = df2
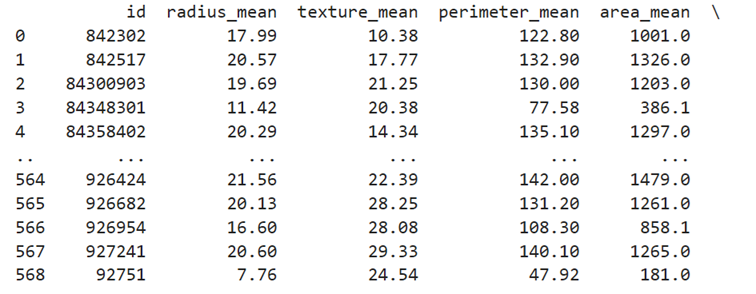
only 11 features are displayed
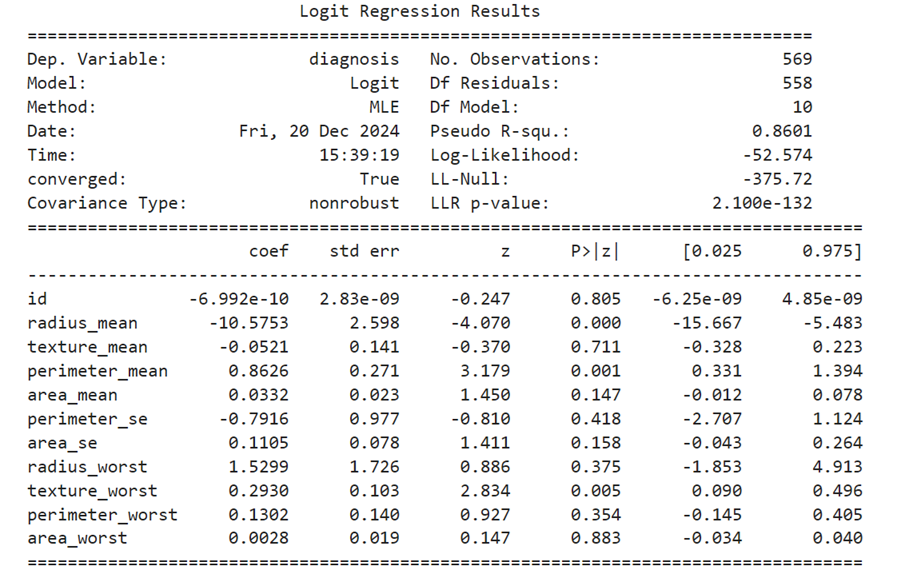
Find Accuracy of the Logistic Regression model:
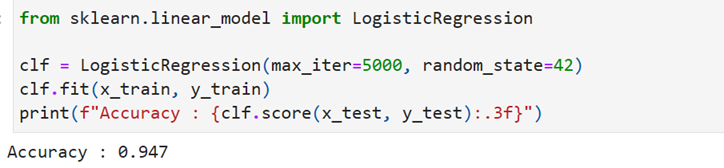
give max_iter more so you do not get error. The accuracy works out to 94.7%

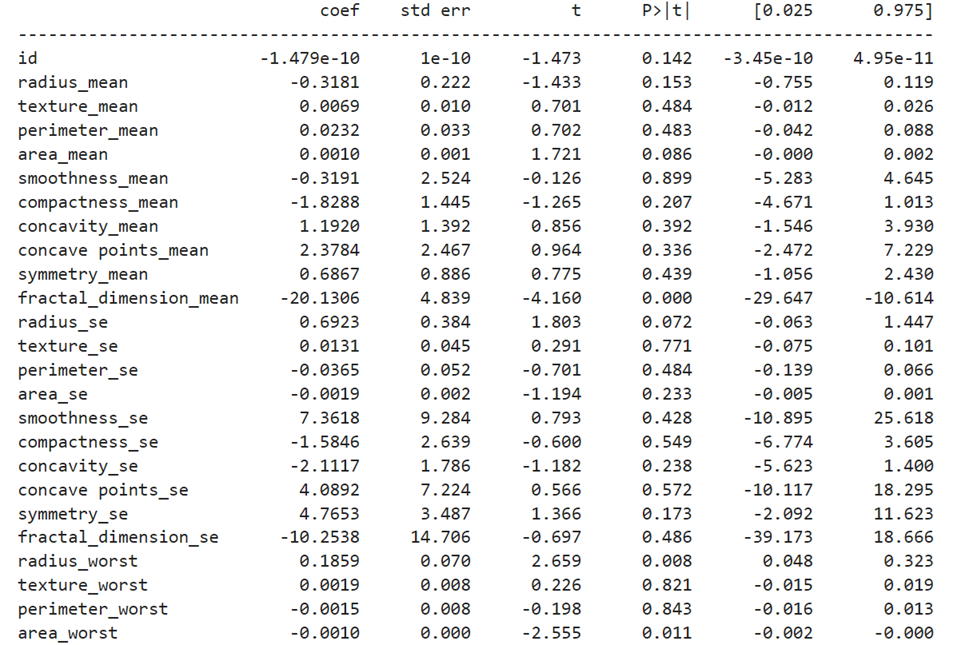
Ordinary Least Square method Model using statsmodels.api

OLS Summary
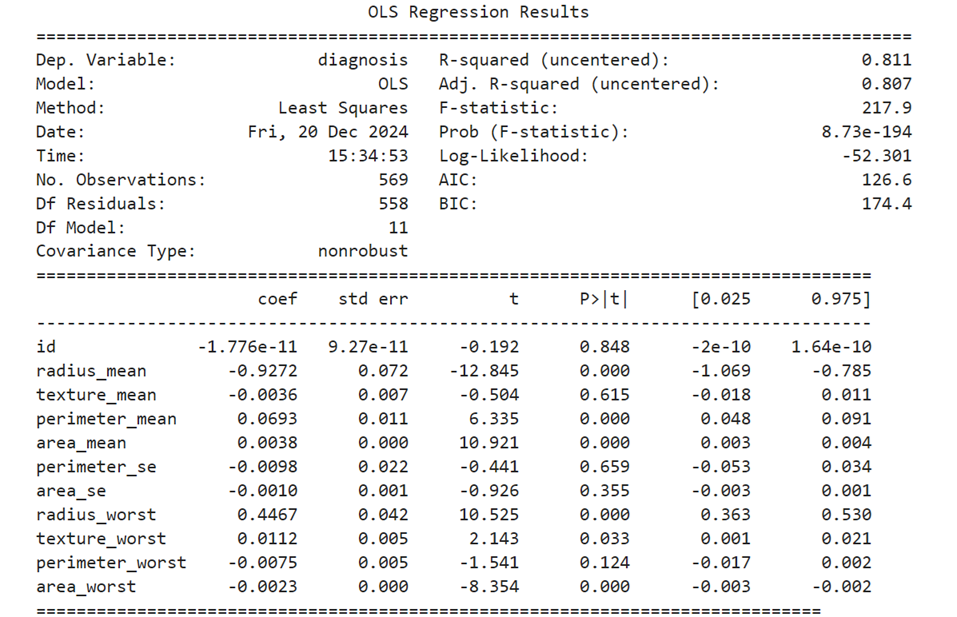

Logistic Regression Model
Since our y dependent variable is dichotomous ( yes or no | 1 or 0) we have to find out betas using Logistic Regression method

If you want to include all 31 features