
Uses the F-test to compare the means of two or more groups and determine if they are significantly different from each other. ANOVA assesses whether the mean differences among groups are larger than expected by chance. Typically used for feature selection in classification problems where the target variable is categorical. It helps in identifying features that significantly differ across target classes. Ex: In a medical dataset, ANOVA can be used to determine if the mean blood pressure differs significantly among different age groups (target classes). Tasks: Step 1: Calculate the ANOVA F-statistic for each feature.Step 2: Compute the p-value for each F-statistic.Step 3: Compare the p-values to a pre-defined significance level (e.g., 0.05).Step 4: Select features with p-values below the significance level.
Let us use the same data available in Kaggle Breast Cancer Wisconsin (Diagnostic) Data Set and reduce the features available. This dataset contains one target/dependent variable and 31 features(independent/explanatory variables).For anova the target variable must be categorical variable. The diagnosis is the target variable. It contains two classes one Malignant and the other one is Benign
Load Libraries:

Read Data:

Find classes of target variable

Convert the classes into 1 or 0 using LabelEncoder lib

view the data
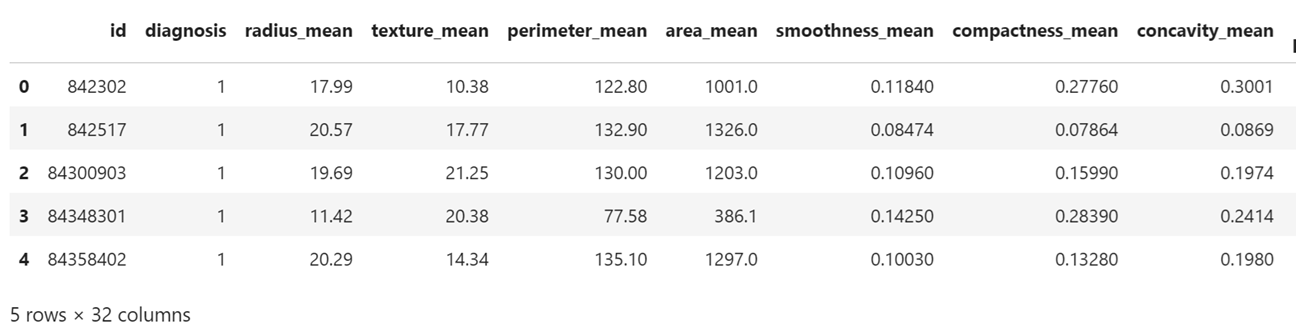
contains 31 features and one targer variable(diagnosis). Now diagnosis classes are converted into 1 or 0
Data Shape:

Separate features and target:

Using numpy convert features and target as float type

Find selected features using F-test, p_value (ANOVA)
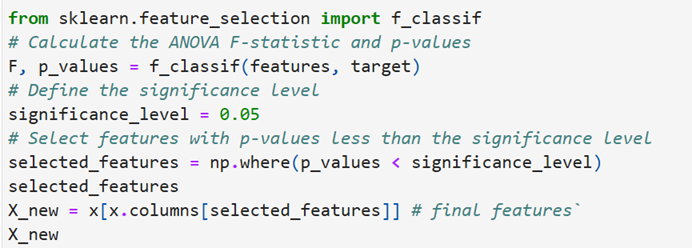
Use f_classif function to calculate F and p_value. Confidential interval is 95%. Significance level is 5% (0.05) if feature’s p_value is less than 0.05 then the feature is statistically significant. The feature must be included for further analysis. If not the feature need not be selected for further analysis. create a new data frame with the selected features based on the comparison of features p_values and the significance level.
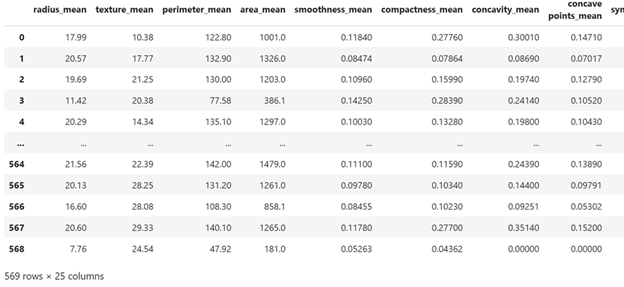
Based on the significance level 25 features out of 31 features have been selected