
As a Predictive Analyst you must be thorough with the following five essential pre-processing techniques. After the collection of raw data, we spend significant amount of time for preparing the data so as to construct a successful model. Our predictive model will be successful only we clean the raw data and convert the raw data into a well-structured data. These pre-processing steps enable you to improve the performance of your model and your insights and reporting
Let us explore the five essential pre-processing techniques.
- Handling missing data
- Encoding of categorical data
- Scaling and normalization of the data
- Feature engineering
- How to deal with imbalanced data
The idea is that our machine learning algorithm should learn the patterns as accurately as possible from the data we input
- Handling of missing data:
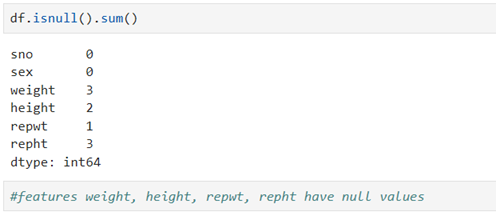
It is quite normal that we may miss data while collecting. It may due to sensor failure, human error or other reasons. Missing data may lead to biased findings/model predictions. Our insights may to go the wrong directions. So, we must address the missing data with a great care so as to preserve the integrity of the dataset we collected.
Handling missing data using Python:
Libraries used a) Pandas and b) sklearn (SciKit learn)
Strategies used: a) deletion, b)mean/mode imputation, c) multi-variate imputation
Types of missing data:
- Missing Completely At Random (MCAR)
- Missing At Random(MAR)
- Missing Not At Random(MNAR)
Missing Completely At Random (MCAR)
- the reason for data missing is unrelated to any observed or unobserved data in the dataset. Missingness is completely random. Example: If a survey assistant unknowingly skips a question, it is a MCAR case. The missing answer is not related to the participants characteristics or other answers they provided. MCAR implies that the probability of a data point being missing is the same for all observations, regardless of their values. Example: some missing values in a variable due to a software error. When data is MCAR, the standard methods that handle missing data can still produce valid and unbiased results. You can use listwise deletion method or mean imputation method
Missing At Random: (MAR)
Here missingness is related to observed data but not to the unobserved data. Ex. missing income data might be related to education level.
Missing Not At Random(MNAR)
Missingness is related to both observed and unobserved data. This is problematic. Handling this is difficult. Ex high-income people might be less likely to disclose their earnings, which can bias the dataset if not handled carefully.
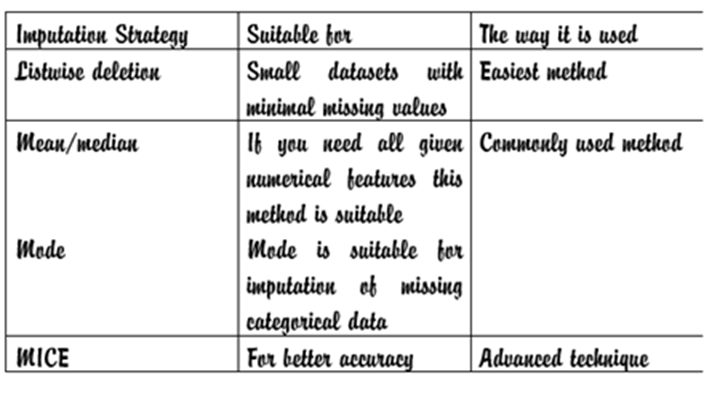
Strategy 1- Listwise Deletion:
The easiest way to handle missing data is to remove the rows that contain missing values. It may work with a small dataset with a few missing data. For a large dataset if many rows contain missing data then the removal of rows may lead to loss of valuable information
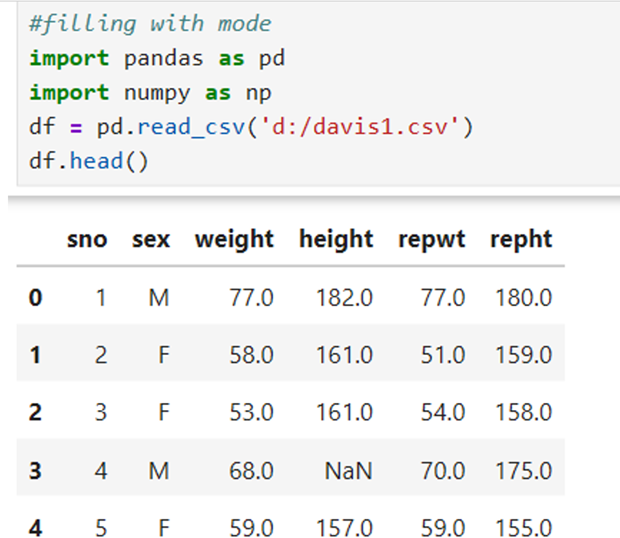
Let us view the following data. It is in the file Davis1.csv
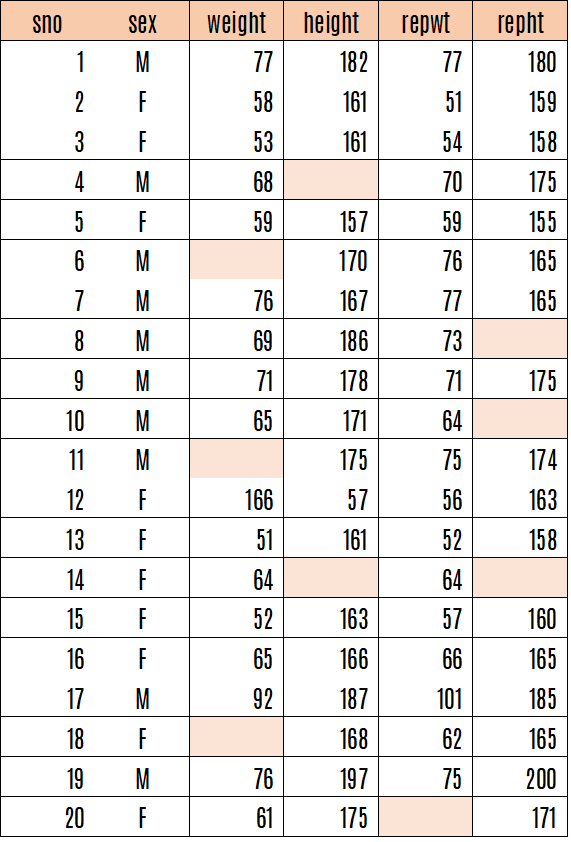
colored cells possess missing values. Missing values hinder the ML processing.
Strategy 1-LISTWISE -DELETION METHOD
Load libraries and read data
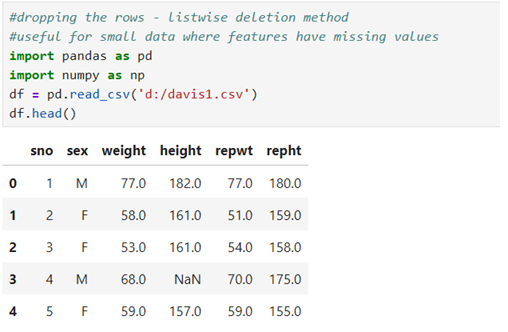
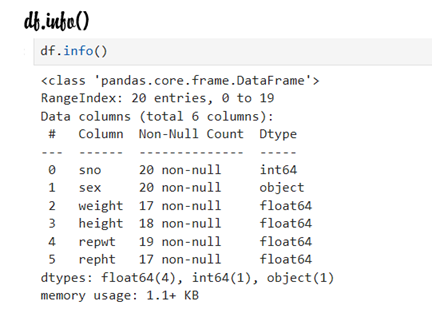
Check if any null values/missing values exist
Remove rows with any missing values
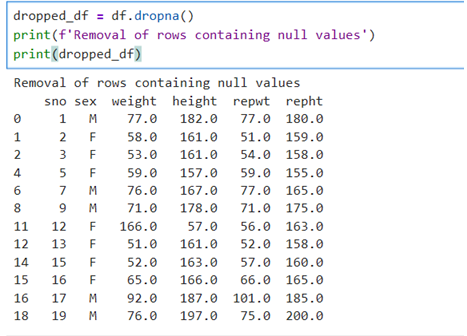
Originally, we had 20 data. After removal of null values, we have 12 data. Check if we have any null values in our data frame after removal
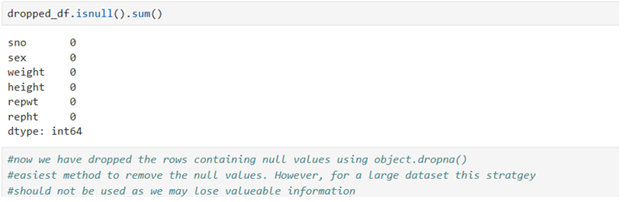
Listwise deletion strategy is suitable for MCAR data only
Strategy 2: Imputation methods (fill in missing items)
If you don’t want to remove the rows or missing values in the dataset you have to fill some value in the missing/Nan items. You can use statistical measures like mean, median or mode for filling the missed items. Imputation allows the user to use all available information. Here no data is discarded as we discarded in the case of listwise deletion method. We impute mean or median when we find NAN/NILL values in any numerical features. This method is suitable when the given data is symmetrically distributed or follow a normal distribution.
But if the given data is left skewed or right skewed, this method will not be suitable as it leads to biased results
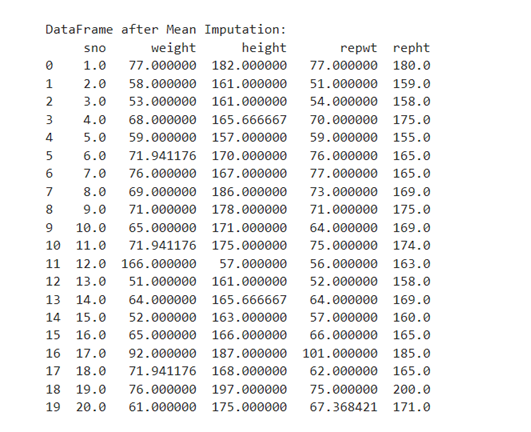
Fill with mean
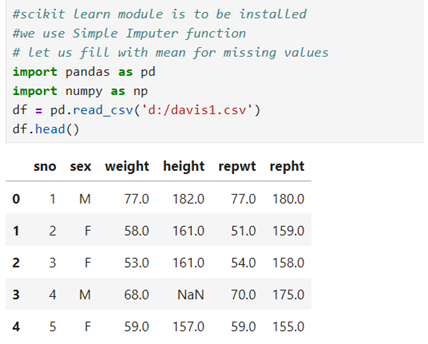
Feature ‘sex’ is having two categories M, F. You can’t impute mean when sex feature is present. So, you have to drop ‘sex’ from the data frame df. Mean/median imputation can work with only numerical data.
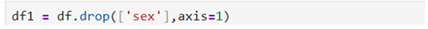
Now the data frame df1 will have only features with numerical data

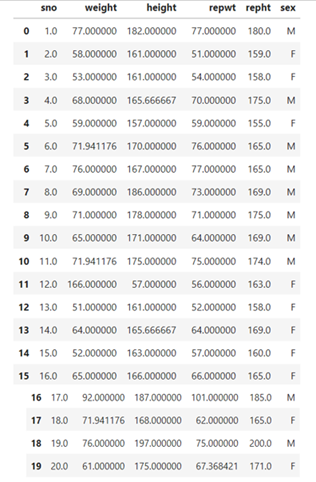
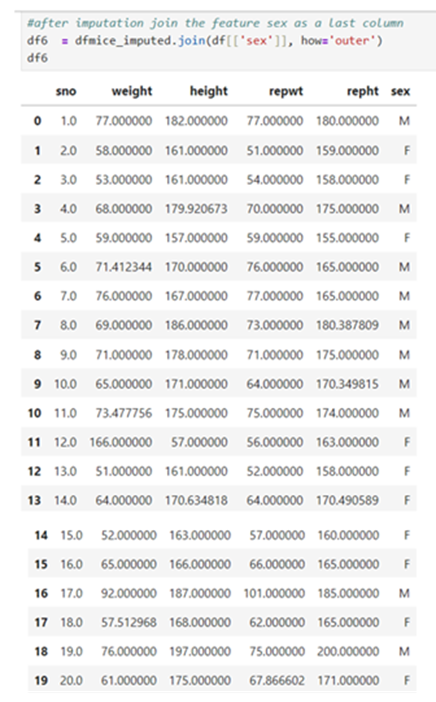
Now you can join the feature ‘sex’ to the extreme right using join function

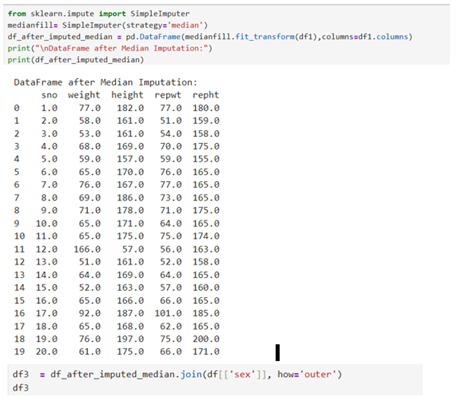
Fill with median
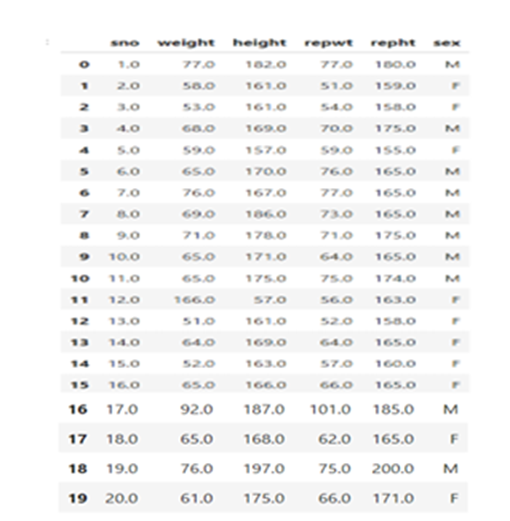
Fill with mode (most frequent)
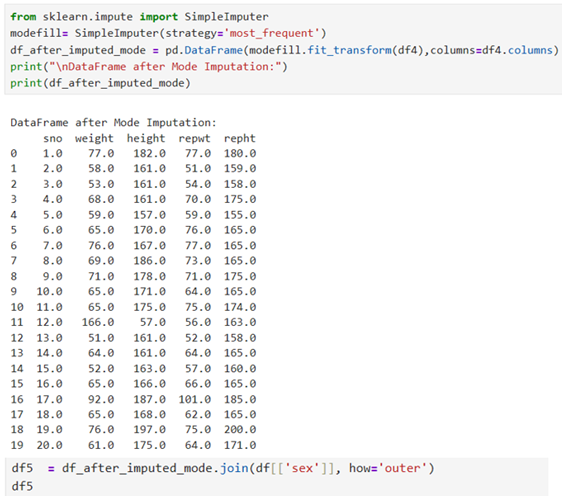
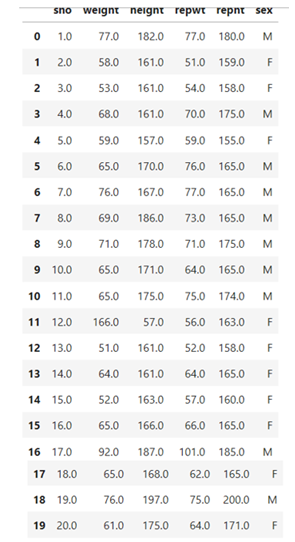
Mean fill method for missing values is suitable/effective for numerical data with minimal skew whereas mode fill method is suitable for skewed data
Mode imputation for categorical data
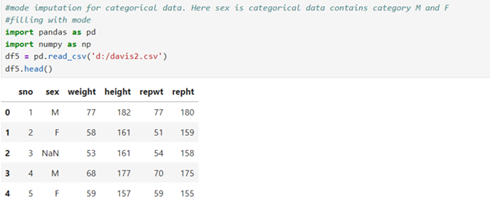
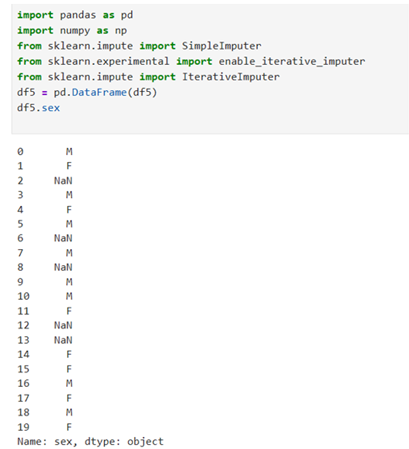

Multivariate imputation by chained Equation(MICE)
This technique predicts missing values based on the relationship between multiple features. MICE iteratively models, each feature with missing values as a function of other features, using regression or other predictive models. This method is more accurate. It considers the data’s structure in a best possible way.
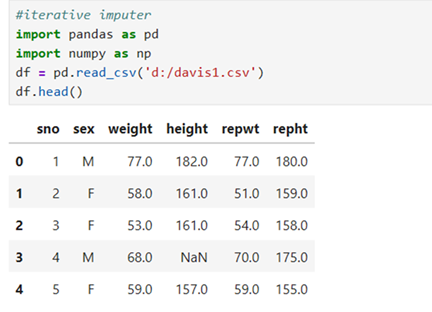
Drop the categorical feature sex and do MICE imputation and then join sex feature as a last column

Do iterative imputation MICE
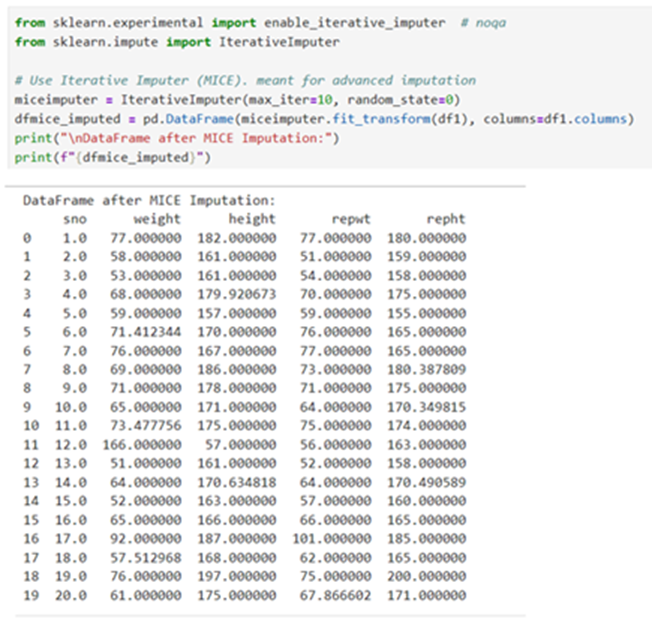
For a successful modelling your selection of Right imputation strategy plays vital role. Handling of missing data is the important step in pre-processing task
Right imputation strategy preserves the integrity of your data and provides a solid foundation for building robust MACHINE LEARNING Models
Reference:
5 Essential Machine Learning Techniques to Master Your Data Preprocessing . A Comprehensive Data Science Guide to Preprocessing for Success: From Missing Data to Imbalanced Datasets. Joseph Robinson, Ph.D.